
MiniGPT-5: A Novel Text-to-Image Generation Approach that Creates Matching Images Alongside Text
-
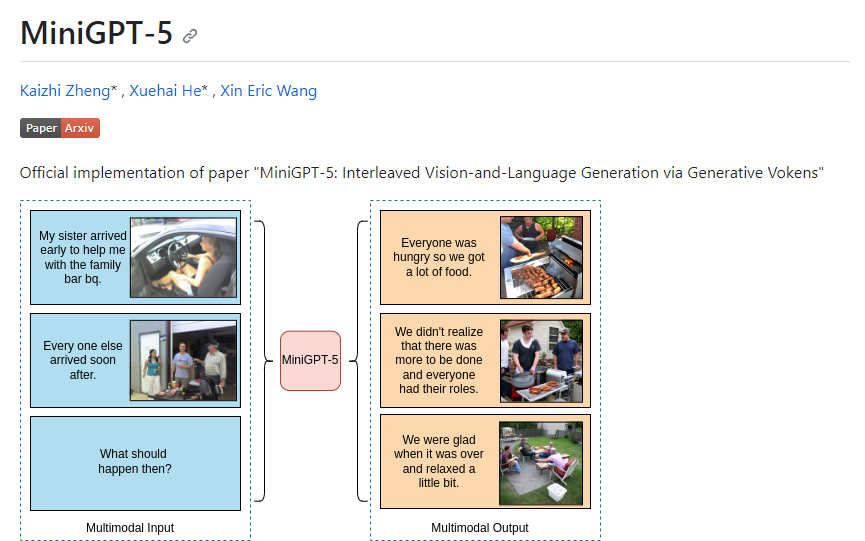
MiniGPT-5 is a vision-language generation tool based on large language models, designed to achieve collaborative generation of images and text. It employs the innovative concept of "generative vokens" as a bridge to realize this multimodal generation.
MiniGPT-5 enhances model robustness through a unique two-stage training strategy focused on multimodal generation without requiring detailed image descriptions. The tool demonstrates excellent performance across multiple benchmark datasets, proving to be a powerful solution for multimodal generation.
Project address: https://github.com/eric-ai-lab/minigpt-5
Core features:
Collaborative Generation: The core functionality of MiniGPT-5 enables simultaneous generation of images and text. Users can input text descriptions to generate corresponding images, or input images to generate related text.
Generative Vokens: This key concept in MiniGPT-5 links text descriptions with image generation, enabling more coordinated multimodal generation.
Two-phase training strategy: This tool adopts a unique two-phase training strategy. The first phase is unimodal alignment, and the second phase is multimodal learning, which helps improve the model's performance.
No detailed descriptions required: MiniGPT-5 can be trained without complex image descriptions, reducing user workload and improving the model's ease of use.
Evaluation function: The tool also provides an evaluation function, allowing performance assessment on multiple datasets to help users understand the model's performance.