
Generative AI - How Do Large Language Models Generate Content?
-
The highly anticipated large language models are centered around natural language understanding and text generation. Have you ever wondered how they comprehend natural language and generate content, and what their working principles are?
To understand this, we must first step outside the realm of large language models and look at machine translation. Traditional machine translation methods still rely on RNN (Recurrent Neural Networks).
Recurrent Neural Networks (RNN) are a type of recursive neural network that takes sequential data as input, recursively processes it in the direction of the sequence, and connects all nodes (recurrent units) in a chain-like manner.
For example, take the sentence "I draw a picture." It would first break it down into four words: "I," "draw," "a," and "picture," then progressively understand and translate the sentence word by word, as shown below:
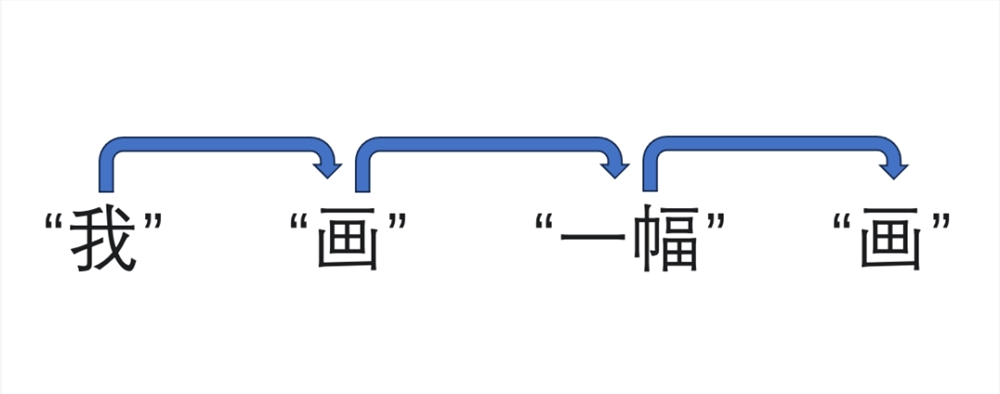
Then, it outputs: "I have drawn a picture."
This method is straightforward, but due to the linear structure of RNNs, they cannot process massive amounts of text in parallel, leading to slow performance. Additionally, they suffer from the "forgetting the beginning when reaching the end" issue, causing vanishing or exploding gradients when handling long sequences.
It wasn't until 2017 that Google Brain and Google Research collaborated on a groundbreaking paper titled Attention Is All You Need, which introduced a novel approach to machine translation processing. The paper also gave it a name inspired by Transformers—Transformer.
The Transformer is a neural network that learns context and meaning by tracking relationships in sequential data. Proposed by Google in 2017, it is one of the most recent and powerful models invented to date.
The Transformer can process massive amounts of text in parallel due to its unique mechanism called the self-attention mechanism. Similar to how our brains focus on key words to better understand a passage while skimming, this mechanism enables AI to achieve the same capability.
Self-attention is a type of attention mechanism that performs linear transformations on the input sequence to generate a distribution of attention weights. It then weights each element of the input sequence based on this distribution to produce the final output.
For example, take the sentence "Please pay attention to waste sorting." When broken down into words like "I," "paint," "a," and "picture," the Transformer processes them through four stages: input, encoder, decoder, and output.
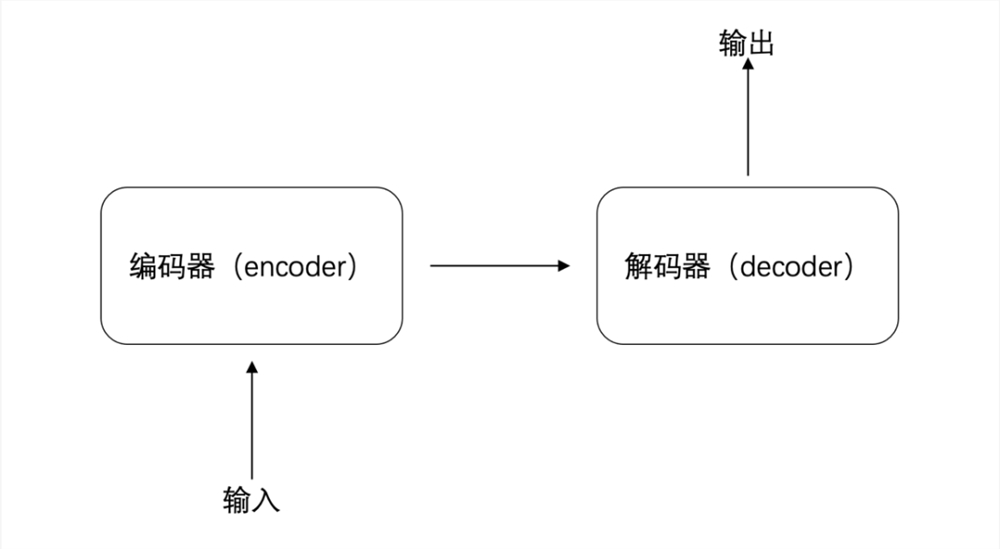
Specifically, after the sentence is split and fed into the encoder, the encoder first generates an initial representation for each word—essentially an initial judgment. For instance, the word "paint" could be interpreted as either a noun or a verb.
Then, using the self-attention mechanism, the degree of association between words is calculated, which can be understood as scoring. For example, the first "paint" has a high association with "me" and is given 6 points, while the second "paint" has a high association with "a" and is given 8 points. "Me" and "a" have little association, so they are given -2 points.
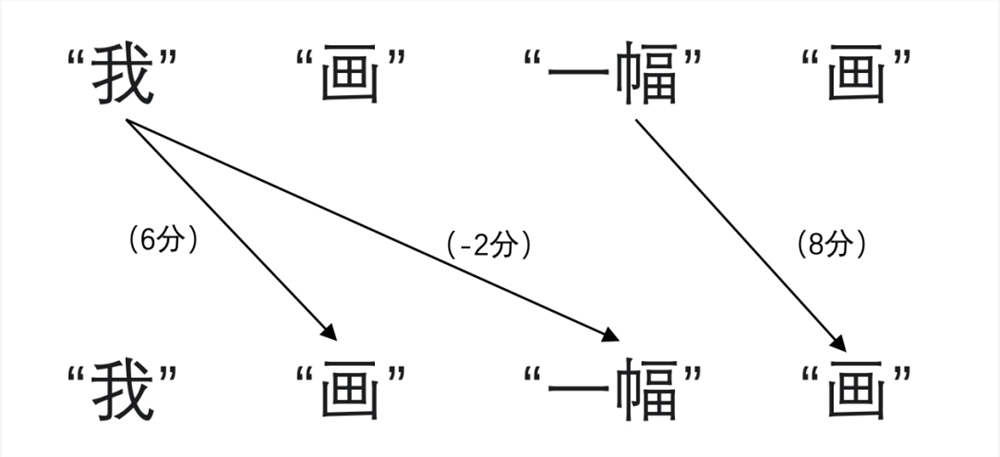
Next, based on the scores, the initial representations are refined. For instance, if the first "paint" has a high association with "me," the representation can reduce the judgment of noun properties and enhance the verb properties. Similarly, if the second "paint" has a high association with "a," the representation can reduce the verb properties and enhance the noun properties.
Finally, the refined representations are input into the decoder, which combines the understanding of each word with the context to output the translation. During this process, all words can be processed simultaneously, significantly improving processing speed.
But what does this Transformer have to do with large language models?
Large language models refer to deep learning models trained on vast amounts of text data, and the Transformer provides the necessary power for such training. Additionally, after the refined representations are input into the decoder, the model can infer the probability of the next word appearing and generate content sequentially from left to right. During this process, it continuously combines previously generated words to infer the next ones.
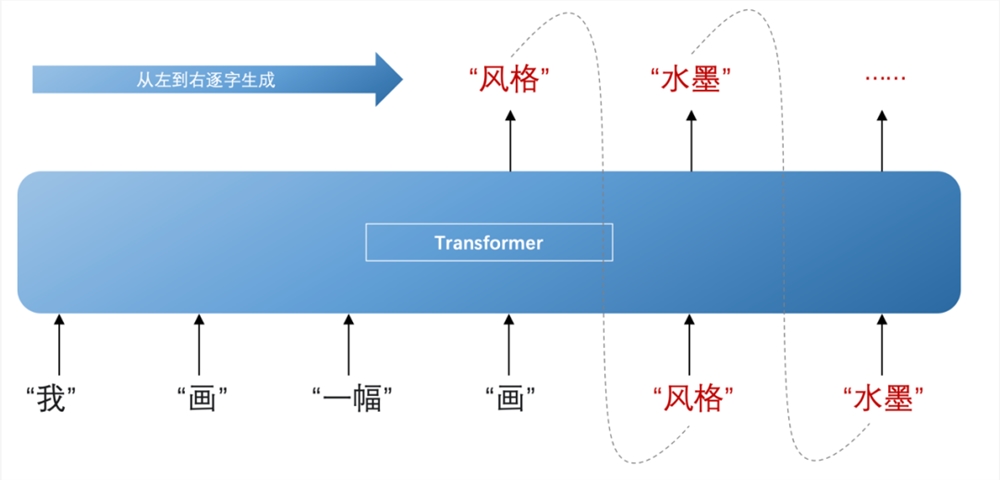
For example, based on the words "a" and "paint," the model might infer that the next word is most likely "style." Then, considering "a," "paint," and "style," it infers the following word as "ink," and so on. This is how large language models generate the content we see.
This is why it's widely believed that the birth of large language models began with Transformer.
So how does the crucial self-attention mechanism in Transformer determine "how much score" to assign?
It involves a relatively complex calculation formula:
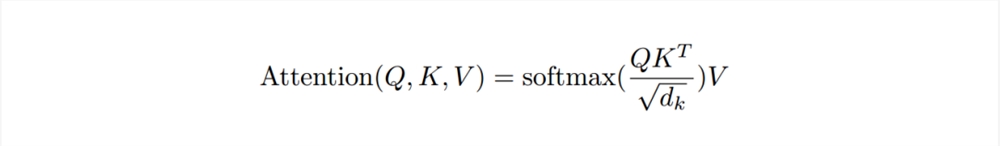
For a simple understanding, think about vector knowledge from math textbooks: when two vectors a and b are in the same direction, a·b=|a||b|; when a and b are perpendicular, a·b=0; when a and b are opposite, a·b=-|a||b|.
If we consider vectors a and b as projections in space of two words from "I", "draw", "a", "picture", then the value of a·b becomes the relevance score.
- The larger this value, the more aligned the vectors' directions, indicating greater word association;
- A value of 0 means the vectors are perpendicular, showing no word association;
- A negative value means the vectors are opposite, indicating not just no association but significant divergence between words.
This is just a simplified explanation. In reality, it requires a complex calculation process with multiple iterations to obtain more accurate information and determine each word's contextual meaning.
The above explains how large language models work. The powerful Transformer is not limited to the field of natural language processing; it also plays a significant role in computer vision and speech processing tasks such as image classification, object detection, and speech recognition. It can be said that the Transformer is the key to the explosive growth of large models this year.
Of course, no matter how powerful the Transformer is, it is only a process for handling inputs. To make the content generated by AI more aligned with our needs, a good input is a crucial prerequisite. So, in the next issue, we will discuss what constitutes a good input and what a Prompt is.