
Multimodal AI Model Unified-IO2: Capable of Understanding and Generating Images, Text, Audio, and Actions
-
Recently, the 'Unified-IO2' jointly developed by researchers from the Allen Institute for Artificial Intelligence, the University of Illinois at Urbana-Champaign, and the University of Washington marks a significant leap in AI capabilities.
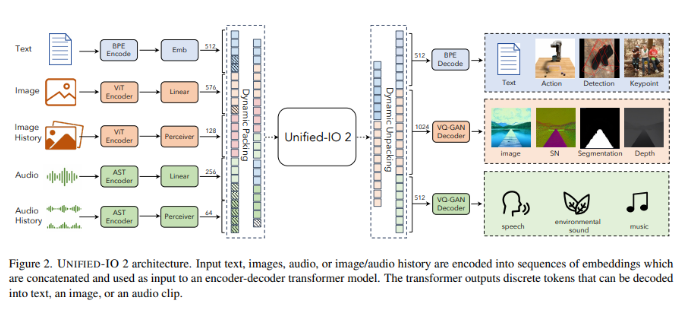
Unlike its predecessors that could only handle dual modalities, Unified-IO2 is an autoregressive multimodal model capable of interpreting and generating various data types such as text, images, audio, and video. As the first model trained from scratch on multimodal data, its architecture is based on a single encoder-decoder transformer model, uniquely designed to convert diverse inputs into a unified semantic space. This innovative approach enables the model to simultaneously process different types of data, overcoming the limitations of previous models in handling multimodal data.
Unified-IO2's approach is both complex and innovative. It utilizes a shared representation space to encode various inputs and outputs, achieved through byte-pair encoding for text and special tokens for encoding sparse structures such as bounding boxes and keypoints. Images are encoded via a pre-trained vision transformer, with linear layers transforming these features into embeddings suitable for transformer input. Audio data undergoes similar processing, being converted into spectrograms and encoded using an audio spectrogram transformer. The model also includes dynamic packing and a mixture of multimodal denoiser objectives to enhance its efficiency and effectiveness in handling multimodal signals.
Unified-IO2 is not only impressive in design but also in performance. Evaluated on over 35 datasets, it sets new benchmarks in the GRIT evaluation, excelling in tasks such as keypoint estimation and surface normal estimation. In vision and language tasks, it matches or even outperforms many recently proposed vision-language models. Particularly noteworthy is its performance in image generation, where it surpasses its closest competitors in fidelity. The model also effectively generates audio from images or text, showcasing its versatility across a broad range of capabilities.
The development and application of Unified-IO2 yield profound conclusions. It represents a significant advancement in artificial intelligence's ability to process and integrate multimodal data, opening up new possibilities for AI applications. Its success in understanding and generating multimodal outputs highlights AI's potential to interpret complex real-world scenarios more effectively. This development marks an important milestone in the field of artificial intelligence, paving the way for future more sophisticated and comprehensive models.

Unified-IO2 symbolizes a beacon of artificial intelligence's intrinsic potential, marking a shift towards more integrated, versatile, and powerful systems. It successfully navigates the complexities of multimodal data integration, setting a precedent for future AI models and heralding an era where AI more accurately reflects and interacts with the multifaceted nature of human experience.
Paper URL: https://arxiv.org/abs/2312.17172