
Google AI Proposes PixelLLM: A Vision-Language Model Capable of Fine-Grained Localization and Visual-Language Alignment
-
The Google AI Research team, in collaboration with researchers from the University of California, San Diego, has proposed an intelligent model called PixelLLM, aimed at tackling the challenges of fine-grained localization and visual-language alignment in large language models. The development of this model was inspired by natural human behaviors, particularly the way infants describe their visual environment through gestures, pointing, and naming.
PixelLLM's uniqueness lies in its successful implementation of precise handling of localization tasks by establishing dense alignment between each output word of the language model and pixel positions. To achieve this, the research team added a miniature multilayer perceptron (MLP) on top of word features, enabling it to regress to the pixel position of each word. The use of low-rank fine-tuning (LoRA) allows the language model's weights to be updated or frozen, while the model can also receive text or location prompts to provide outputs customized according to the prompts.
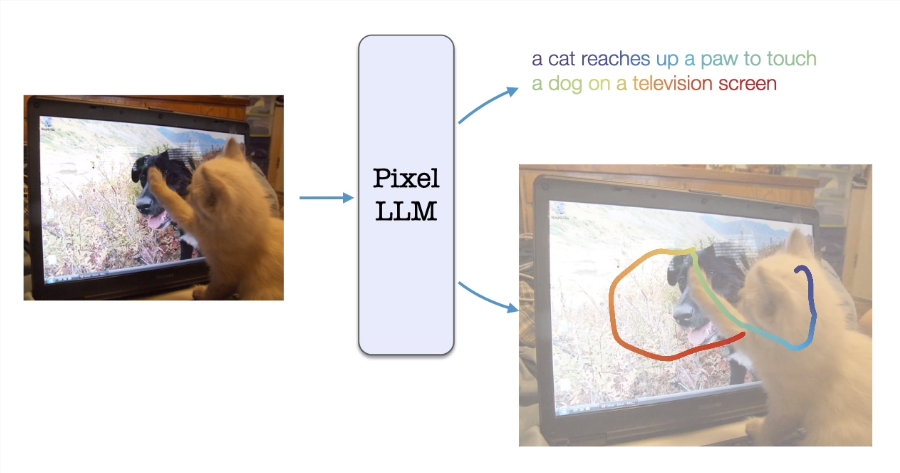
The overall architecture of PixelLLM includes an image encoder, a prompt encoder, and a prompt feature extractor. The large language model is fed with picture features conditioned on prompts and optional text prompts, outputting the localization and captions for each word. This architecture offers diverse combinations of input or output languages or locations, providing flexibility and adaptability for various visual-language activities.
The research team evaluated PixelLLM on visual tasks including dense object captioning, location-conditioned captioning, and referring localization. Impressive performance metrics include 89.8P@0.5 on RefCOCO referring localization, 19.9CIDEr on Visual Genome conditioned captioning, and 17.0mAP on dense object captioning. Ablation studies conducted on RefCOCO showed that PixelLLM achieved a 3.7-point gain with dense pixel localization formulation compared to other localization approaches.
PixelLLM's key contributions are summarized as follows:
-
Introduced a novel vision-language model PixelLLM capable of generating word-level localization and image captions.
-
The model supports text or optional location prompts in addition to image input.
-
Utilized localized narrative datasets for per-word localization training.
-
The model can adapt to various vision-language tasks, including segmentation, location-conditioned captioning, referring grounding, and dense description.
-
The model demonstrates outstanding performance in location-conditioned captioning, dense description, referring grounding, and segmentation.
This research achievement marks an important advancement in the field of large language models, opening new possibilities for achieving more precise vision-language alignment and localization.
Project demo URL: https://top.aibase.com/tool/pixelllm
Paper URL: https://arxiv.org/abs/2312.09237
-