
Tongyi Qianwen 72B Model Tops the Large Model Evaluation Platform Rankings
-
China's authoritative large model evaluation platform OpenCompass recently updated its rankings, with the Tongyi Qianwen 72B model taking the top spot with a high score of 67.1.
OpenCompass is an open-source large model evaluation platform launched by the Shanghai Artificial Intelligence Laboratory. Its evaluation scope covers five dimensions: disciplines, language, knowledge, comprehension, and reasoning, providing a comprehensive assessment of large model capabilities.
In OpenCompass's Chinese dataset evaluations, the Qwen-72B base large model and the conversational large model (Qwen-72B-Chat) secured the top two positions, significantly outperforming other models.
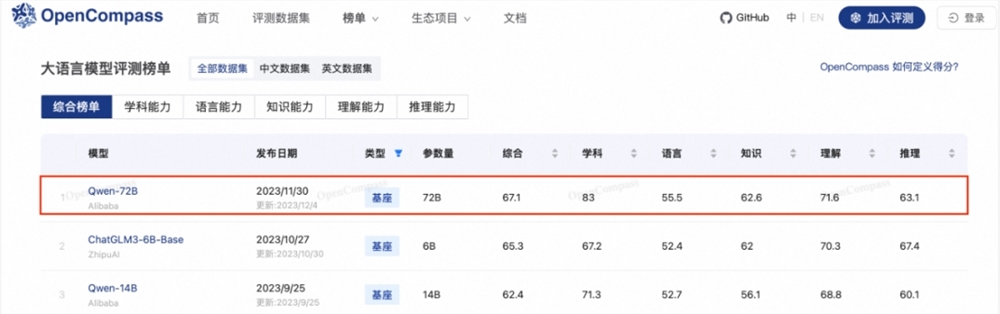
In early December, Alibaba Cloud announced the open-sourcing of its 72-billion-parameter large language model, Qwen-72B. Qwen-72B has achieved the best performance among open-source models in ten authoritative benchmark evaluations, making it the most powerful open-source large model in the industry. Its performance surpasses the open-source benchmark model Llama2-70B and most commercial closed-source models, making it suitable for enterprise-level and research-level high-performance applications.
It is reported that Qwen-72B can process text inputs of up to 32k in length and outperforms ChatGPT-3.5-16k on the long-text understanding test set LEval.