
Meta AI Open-Sources T2V Model AVID Capable of Video Restoration and Texture Alteration
-
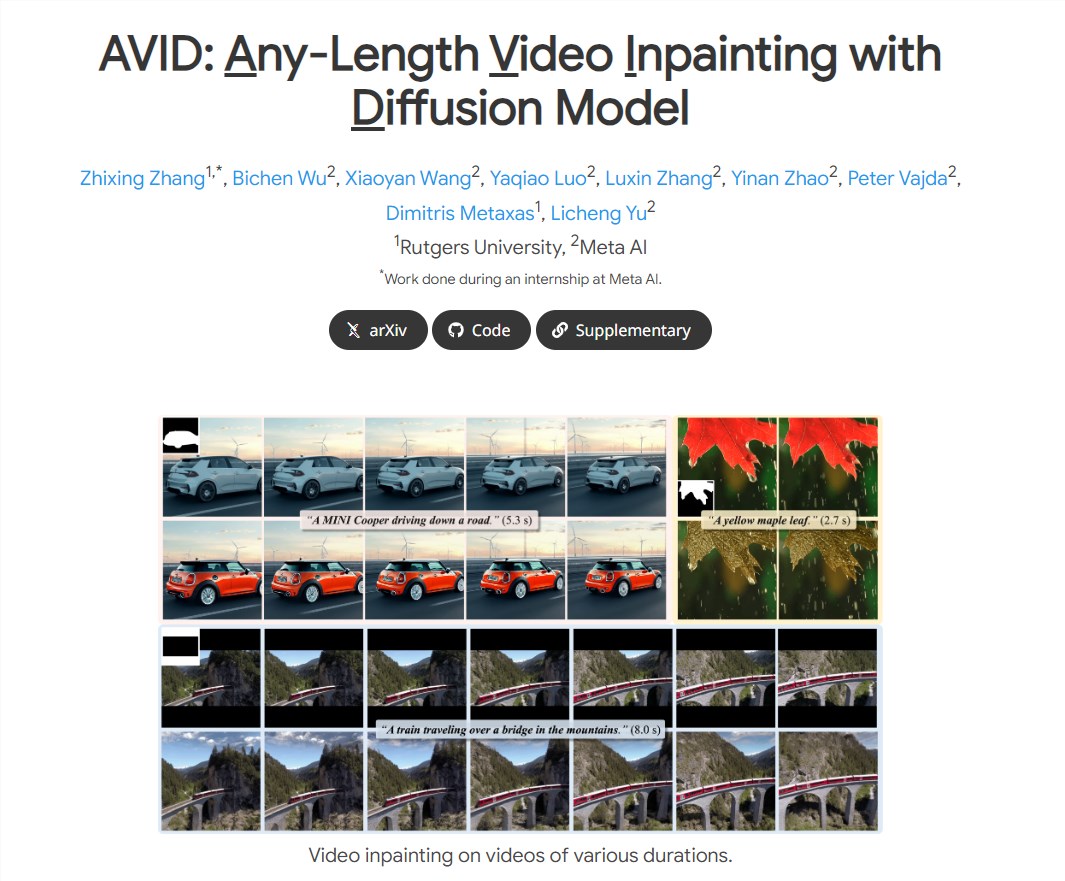
Meta AI recently open-sourced AVID, a T2V model with advanced restoration and expansion capabilities. AVID not only supports text-based video editing but can also repair videos, modify video objects, alter textures and colors, and even remove video content or change video environments.
Project address: https://zhang-zx.github.io/AVID/
This open-source project aims to address three main challenges in text-guided video restoration: temporal consistency, support for different fidelity levels, and handling variable video lengths.
The AVID model is equipped with effective motion modules and adjustable structural guidance, making it suitable for fixed-length video inpainting. Additionally, the model introduces a novel temporal multi-diffusion sampling pipeline with a mid-frame attention guidance mechanism, facilitating the generation of videos of any desired duration. Comprehensive experiments demonstrate that the AVID model robustly handles various inpainting types across different video durations with high quality.
During the training phase, the AVID model adopts a two-step approach. First, motion modules are integrated after each layer of the primary text-to-image (T2I) inpainting model, and the video data is optimized. Second, the parameters in the UNet $\epsilon_\theta$ are retained, and a structural guidance module $\mathbf{s}_\theta$ is specifically trained using a copy of the UNet encoder's parameters. During inference, for a video of length $N^\prime$, the AVID model constructs a series of segments, each containing $N$ consecutive frames, and computes and aggregates the results for each segment at every denoising step.