
ChatGPT Models Excel in Neurology Exams, Surpassing Human Student Performance
-
A recent study published in JAMA Network Open evaluated two ChatGPT large language models (LLMs) in answering questions from the American Board of Psychiatry and Neurology question bank. The researchers compared the performance of these models on both basic and advanced questions with that of human neurology students. The study found that one of the models significantly outperformed the human average score (85% vs. 73.8%) on the written exam, thereby passing the notoriously difficult entrance test. These findings underscore the latest advancements in LLMs and demonstrate how, with minor adjustments, they could become critical resources in clinical neurology applications.

Image credit: AI-generated image, image licensing service provider Midjourney
With the advancement of computational power and the development of 'smarter' AI models, machine learning (ML) and other artificial intelligence (AI) algorithms are increasingly being applied to fields previously limited to humans, including medicine, military, education, and scientific research. Recently, transformer-based AI architectures—AI algorithms trained on 45TB or more of data—are assisting or even replacing roles traditionally performed by humans, including in neurology. The vast amount of training data, combined with continuously improving code, enables these models to deliver logical and accurate responses, recommendations, and predictions. The two main algorithms currently developed on the ChatGPT platform are LLM1 (ChatGPT version 3.5) and LLM2 (ChatGPT 4). The former is less computationally demanding and processes data faster, while the latter is more contextually accurate.
Although informal evidence supports the utility of these models, their performance and accuracy have rarely been tested in scientific settings. Limited existing evidence comes from studies on LLM1's performance in the US Medical Licensing Examination (USMLE) and ophthalmology exams, while the LLM2 version has not yet been validated.
Study Details:
In this study, researchers aimed to compare the performance of LLM1 and LLM2 with that of human neurology students in a simulated board written examination. This cross-sectional study adhered to the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) guidelines and used the neurology board examination as a proxy for the performance of LLM1 and LLM2 in highly technical human medical exams. The study utilized questions from the American Board of Psychiatry and Neurology (ABPN) question bank. The bank contained 2,036 questions, of which 80 were excluded due to being video or image-based. LLM1 and LLM2 were sourced from online servers (ChatGPT 3.5 and 4, respectively) and were trained up to September 2021. Human comparison data were derived from actual performance in previous versions of the ABPN board entrance examination.
Testing Process:
During the evaluation process, the pre-trained models LLM1 and 2 were unable to access online resources to verify or improve their answers. No neurology-specific model tuning or fine-tuning was conducted before the model testing. The testing process involved submitting the models to 1,956 multiple-choice questions, each with one correct answer and three to five distractors. According to Bloom's Taxonomy of Learning and Evaluation, all questions were categorized as either low-order (basic understanding and memory) or high-order (application, analysis, or evaluation-based thinking) questions.
Performance Evaluation:
The evaluation criteria considered a score of 70% or higher as the minimum passing grade for the exam. The reproducibility of the models' answers was tested through 50 independent queries designed to explore the principle of self-consistency.
Statistical Analysis:
Statistical analysis included univariate, order-specific comparisons between model performance and previous human results, using the chi-square (χ2) test (with Bonferroni correction for 26 identified question subgroups).
Research findings:
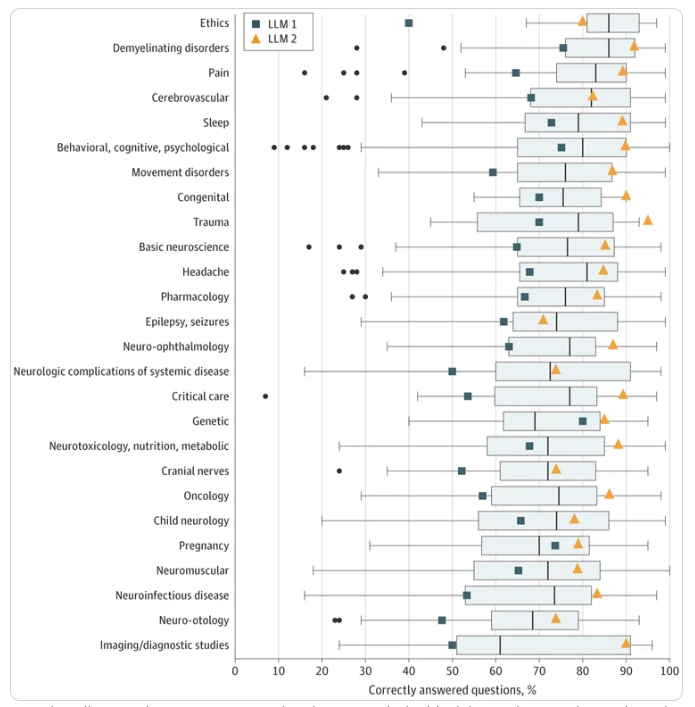
LLM2 performed best among all test groups, achieving a score of 85.0% (1662 correct answers out of 1956 questions). In comparison, LLM1 scored 66.8%, while the human average was 73.8%. The model showed highest performance in lower-order questions (71.6% and 88.5% for models 1 and 2 respectively).
In this study, researchers evaluated the performance of two ChatGPT LLMs in neurology board exams. They found that the later model significantly outperformed the earlier model and human neurology students in both lower-order and higher-order questions. Although stronger in memory-based questions, these results highlight the potential of these models to assist or even replace human medical experts in non-critical tasks.
Notably, these models were not fine-tuned for neurology purposes nor allowed access to continuously updated online resources, both of which could further widen the performance gap between them and human creators.