
Google Releases Cloud TPU v5p and AI Supercomputer
-
Google has made waves with the launch of its Tensor Processing Unit Cloud TPU v5p and the groundbreaking supercomputer architecture AI Hypercomputer. These innovative releases, along with the resource management tool Dynamic Workload Scheduler, mark a significant step forward in handling organizational AI tasks.

Cloud TPU v5p, following the release of v5e last November, becomes Google's most powerful TPU. Unlike its predecessor, v5p is designed with performance in mind, promising significant improvements in processing power. Each pod is equipped with 8,960 chips, with inter-chip connectivity reaching 4,800Gbps. This version delivers double the performance in floating-point operations per second (FLOPS) and triples the high-bandwidth memory (HBM) compared to the previous TPU v4.
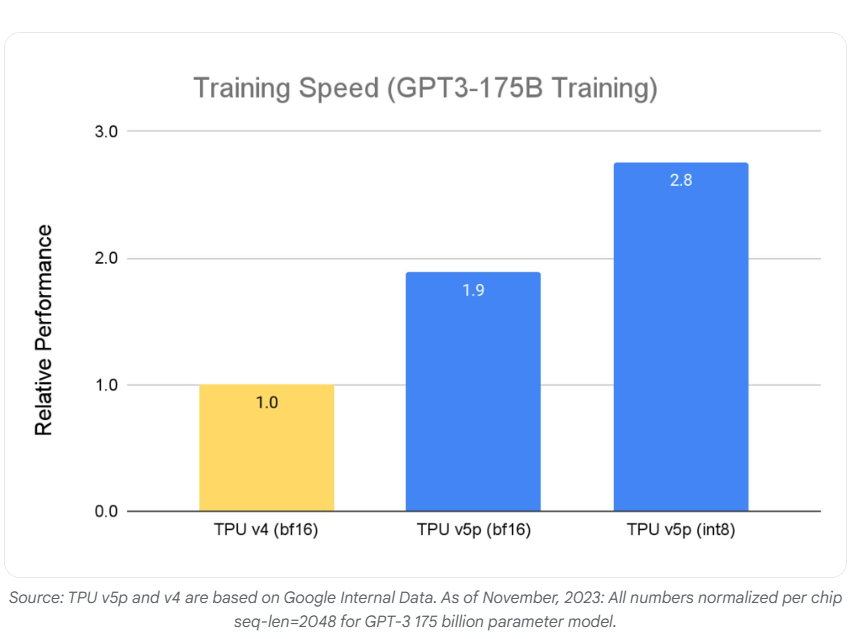
The focus on performance has yielded remarkable results, with Cloud TPU v5p achieving an astonishing 2.8x faster training speed for large LLM models compared to TPU v4. Additionally, leveraging second-generation SparseCores, v5p demonstrates 1.9x faster training speed for embedded dense models than its predecessor.
Meanwhile, AI Hypercomputer represents a revolutionary transformation in supercomputing architecture. It combines optimized performance hardware, open-source software, major machine learning frameworks, and adjustable consumption models. Departing from traditional approaches that reinforce discrete components, AI Hypercomputer employs collaborative system design to enhance AI efficiency and productivity in training, fine-tuning, and service domains.
This advanced architecture is built upon meticulously optimized hyperscale data center infrastructure for computation, storage, and networking. Furthermore, it provides developers with access to relevant hardware through open-source software, supporting machine learning frameworks such as JAX, TensorFlow, and PyTorch. This integration extends to software like Multislice Training and Multihost Inferencing, while deeply incorporating Google Kubernetes Engine (GKE) and Google Compute Engine.
The truly distinctive feature of AI Hypercomputer lies in its flexible consumption model, specifically designed to meet AI task requirements. It introduces innovative solutions like the Dynamic Workload Scheduler alongside traditional consumption models including Committed Use Discounts (CUD), on-demand, and Spot pricing. This resource management and task scheduling platform supports both Cloud TPUs and Nvidia GPUs, simplifying the scheduling of all required accelerators to optimize user expenditure.
Under this model, the Flex Start option is ideal for model fine-tuning, experiments, shorter training sessions, offline inference, and batch processing tasks. It provides a cost-effective way to request GPU and TPU capacity before execution. Conversely, the Calendar mode allows for scheduling specific start times, catering to training and experimental tasks that require precise start times and durations, available for purchase up to 8 weeks in advance, lasting 7 or 14 days.
Google's release of Cloud TPU v5p, AI Hypercomputer, and Dynamic Workload Scheduler represents a major leap in AI processing capabilities, ushering in a new era of performance enhancement, optimized architecture, and flexible consumption models. These innovations are expected to redefine the landscape of AI computing and pave the way for groundbreaking advancements across various industries.
Official blog URL: https://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-tpu-v5p-and-ai-hypercomputer