
Peking University and Others Release the Latest AI Agent Jarvis-1
-
[New Zhiyuan Introduction] A research team from Peking University, BUPT, UCLA, and BIGAI jointly announced a new breakthrough in agents—Jarvis-1.
Agent research has achieved new milestones!
Recently, a research team from Peking University, BUPT, UCLA, and BIGAI published a paper introducing an agent called Jarvis-1.
Paper address: https://arxiv.org/pdf/2311.05997.pdf
Judging from the paper's title, Jarvis-1 is packed with impressive features.
It is a multimodal + memory-augmented + multi-task processing open-world language model that excels at playing the game "Minecraft".
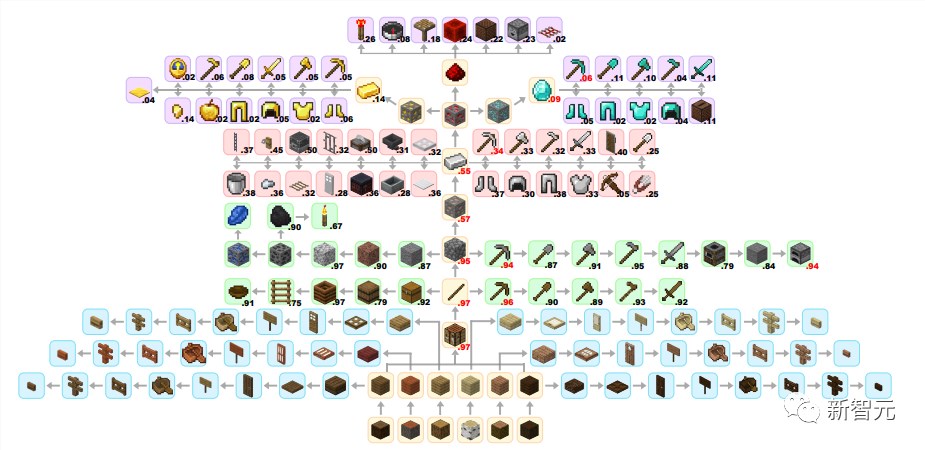
Image: Jarvis-1 unlocking the Minecraft tech tree
In the paper abstract, the researchers stated that in an open world, achieving human-like planning and control capabilities through multimodal observation is an important milestone for more powerful general-purpose agents.
It is worth noting that existing methods can indeed handle certain long-term tasks in open worlds. However, the number of tasks in an open world may be infinite, in which case traditional methods struggle and lack the ability to gradually improve task completion over time.
Jarvis-1 is different. It can perceive multimodal inputs (including self-observation and human instructions), generate complex plans, and execute embedded control. All these processes can be implemented in the open-world game "Minecraft."
Let's take a look at what sets Jarvis-1 apart from other intelligent agents.
Implementation Process
Specifically, researchers developed Jarvis-1 based on a pre-trained multimodal language model, mapping observations and textual instructions into plans.
These plans are ultimately assigned to goal-conditioned controllers. The researchers equipped Jarvis-1 with a multimodal memory, enabling it to utilize both pre-trained knowledge and practical gaming experience for corresponding planning.
In the researchers' experiments, Jarvis-1 demonstrated near-perfect performance across more than 200 different tasks (from beginner to intermediate levels) in the "Minecraft" benchmark.
For example, Jarvis-1 achieved an impressive 12.5% completion rate in the long-sequence task of synthesizing diamond pickaxes.
This data indicates that compared to previous records, Jarvis-1's completion rate for diamond pickaxe tasks has improved by 5 times, far surpassing the previous SOTA-level VPT's performance on this task.
Additionally, the paper demonstrates how Jarvis-1 utilizes multimodal memory to self-improve under lifelong learning paradigms, thereby stimulating broader intelligence and enhancing autonomy.
In the skill tree unlocking image at the beginning of the article, Jarvis-1 can consistently obtain numerous advanced items from Minecraft's main tech tree, such as diamonds, redstone, and gold.
It's worth noting that acquiring these items requires collecting over 10 different intermediate materials.
The following image more intuitively demonstrates the challenges in an open-world environment and how Jarvis-1 addresses them.
On the far left, compared to GPT, which does not employ context-aware planning, Jarvis-1 significantly improves the success rate in the challenging task of acquiring diamonds. The blue line represents human completion rates, limited to a 10-minute timeframe under experimental conditions.
The middle diagram shows that as task complexity increases (stone → iron ore → diamond), Jarvis-1 demonstrates a significant advantage through interactive planning, far outperforming GPT.
On the right, the illustration indicates how much the success rate improves for selected tasks (x-axis) by retrieving contextual experience from multimodal memory for other tasks (y-axis), represented by the intensity of the colors.
It is evident that through lifelong learning and memory, Jarvis-1 can utilize prior experience from related tasks to enhance its planning for current tasks.
Having discussed these performance advantages, Jarvis-1's exceptional capabilities and superiority over GPT can be attributed to three key factors:
- From LLM to MLM
First, we recognize that the ability to perceive multimodal sensory inputs is crucial for models to plan effectively in dynamic and open environments.
Jarvis-1 achieves this by integrating multimodal foundation models with LLMs. Unlike LLMs that generate plans blindly, MLMs can naturally comprehend the current context and formulate appropriate plans accordingly.
Additionally, multimodal perception can provide rich environmental feedback, helping planners to self-check and self-explain, identify and correct potential errors in plans, and achieve stronger interactive planning.
- Multimodal Memory
Previous studies have shown that memory mechanisms play a crucial role in the operation of general-purpose intelligent agents.
By equipping Jarvis-1 with multimodal memory, researchers enable it to effectively utilize pre-trained knowledge and practical experience for planning, significantly improving the accuracy and consistency of plans.
Compared to typical RL or exploration-capable agents, the multimodal memory in Jarvis-1 allows it to leverage these experiences in non-textual ways, eliminating the need for additional model update steps.
- Self-Directed Learning and Improvement
A hallmark of general-purpose agents is their ability to actively acquire new experiences and continuously self-improve. With the integration of multimodal memory and exploratory experiences, researchers have observed Jarvis-1's steady progress, particularly when tackling more complex tasks.
Jarvis-1's autonomous learning capability signifies a critical step in this research toward general-purpose agents—intelligent systems that can continuously learn, adapt, and refine themselves with minimal external intervention.
Key Challenges
Of course, many difficulties will be encountered in the process of developing open-world games. Researchers indicate there are three primary challenges.
First, an open world means there isn't just one path to complete a task. For example, if the task is to make a bed, the AI agent could collect wool from sheep, gather spider webs, or even trade with NPC villagers in the game. Choosing the optimal approach in real-time requires the agent to have situational awareness (situation-aware planning). In other words, it needs to accurately assess the current circumstances.
During experiments, the AI agent sometimes made incorrect judgments, leading to inefficient task completion or outright failure.
Second, when executing highly complex tasks, a single mission often consists of numerous subtasks (20+). Completing each subtask isn't easy either, as the conditions are often stringent.
Third, there's the issue of lifelong learning (lifelong learning).
After all, the number of tasks in an open world is countless, making it impractical for an intelligent agent to learn them all in advance. This necessitates the agent to continuously learn during the planning process, known as lifelong learning. The performance of Jarvis-1 in this regard has already been mentioned in the previous section.
Overall Framework
The overall framework of Jarvis-1 is shown in the figure below.
The left side of the figure includes a memory-augmented multimodal language model (MLM) and a low-level action controller, with the former capable of generating plans.
At the same time, Jarvis-1 can utilize a multimodal memory to store and retrieve experiences as references for further planning.
As shown in the figure below, the middle part illustrates the flowchart of how Jarvis-1 uses MLM to generate plans, which is concise and easy to understand.
Upon receiving a task, the MLM starts providing suggestions, which are sent to the planner to ultimately generate a plan. The multimodal memory bank can be accessed at any time, and newly generated plans are stored as learning materials.
For example, consider a task to obtain diamond ore.
The MLM begins planning—the green box at the top right represents the initial plan. After self-checking, it identifies missing items and adjusts the plan accordingly, correcting the quantities of items to be obtained.
After receiving feedback from the multimodal model, during execution, it was discovered that the task failed. A random self-check of the current state was conducted, such as finding that the pickaxe was broken. Upon checking the inventory, it was found that there were still materials available to generate a new pickaxe, so work began. Of course, this step also includes a self-explanation (self-explain) process.
Ultimately, a new plan was generated, and the task was finally completed.
The following diagram illustrates how Jarvis-1 generates query results.
First, it examines the current observations and tasks. Jarvis-1 employs reverse thinking to identify the necessary intermediate sub-goals.
Naturally, the depth of reasoning is limited. The sub-goals stored in memory are combined with the current observations to form the final query results.
Entries matching the text query are then sorted based on their status and perceptual distance from the observation query, with only the top entry from each subgoal being retrieved.
In the experimental phase, the tasks selected by the researchers were all drawn from the recently released Minecraft benchmark.
Before the experiment began, the setup was as follows:
Environment Setup~To ensure game realism, the agent needed to utilize observation and action spaces similar to humans. Instead of manually designing custom interfaces for model-environment interaction as in previous methods, the researchers opted to use Minecraft's native human interface.
This applies to both observation and action by the agent. The model runs at 20 frames per second and requires mouse and keyboard interfaces for interaction with human graphical user interfaces.
- Task Setting
In Minecraft, players can obtain thousands of items, each with specific acquisition requirements or recipes. In survival mode, players must gather various items from the environment or craft/smelt items using materials.
Researchers selected over 200 tasks from the Minecraft benchmark for evaluation. For statistical convenience, these tasks were divided into 11 groups based on recommended categories in Minecraft, as shown in the figure below.
Due to the varying complexity of these tasks, the team adopted different maximum game durations for each task.
- Evaluation Metrics
By default, the AI always plays in survival mode with an empty initial inventory.
If the target object is obtained within the specified time, the task is considered successful. Due to the open-world nature of Minecraft, the world and initial position where the agent starts can vary significantly.
Therefore, researchers conducted at least 30 tests per task using different seeds (similar to a map generation code) and reported the average success rate to ensure a more comprehensive evaluation.
The left side of the figure below shows the game success rate of Jarvis-1, along with a comparison with the VPT model.
The right side displays the success rate of Jarvis-1 in acquiring intermediate items during task execution. It can be observed that the success rate remains quite high over time.
References: