
HIT Shenzhen Releases Multimodal JiuTian-LION Large Model
-
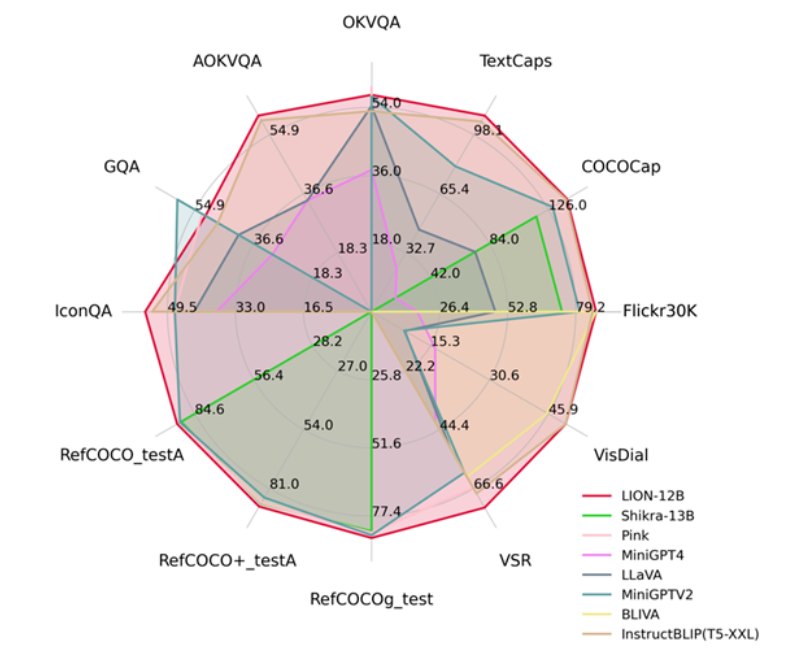
Harbin Institute of Technology (Shenzhen) recently released the JiuTian-LION multimodal large language model, which achieves state-of-the-art performance on 13 vision-language tasks by integrating fine-grained spatial perception and high-level semantic visual knowledge, with a particularly notable 5% performance improvement on Visual Spatial Reasoning tasks.
Paper link: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
Project homepage: https://rshaojimmy.github.io/Projects/JiuTian-LION
Traditional multimodal large language models have deficiencies in visual information extraction, leading to issues such as visual localization bias and hallucinations. The Jiutian model resolves these problems through a dual-layer visual knowledge enhancement strategy.
Its methodological framework includes a segmented instruction fine-tuning strategy and a hybrid adapter. For the first time, it analyzes the internal conflict between image-level understanding tasks and region-level localization tasks, achieving mutual improvement in both tasks. By injecting fine-grained spatial awareness and high-level semantic visual knowledge, Jiutian has achieved significant performance improvements across 17 visual-language tasks, including image captioning, visual question answering, and visual localization. Among these, 13 evaluation tasks have reached internationally leading levels.
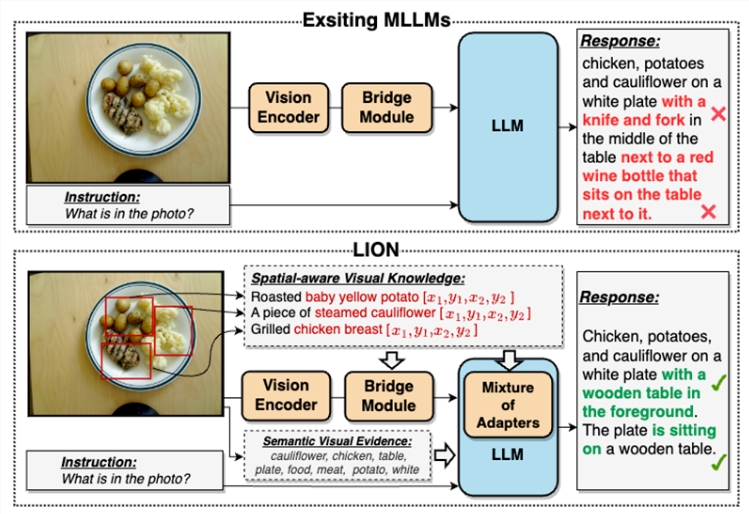
Compared to existing multimodal large language models, Jiutian effectively enhances visual understanding capabilities by progressively integrating fine-grained spatial awareness visual knowledge and high-level semantic visual evidence under soft prompts. This results in more accurate textual responses and reduces model hallucinations. Overall, Jiutian brings new ideas and performance breakthroughs to the field of multimodal large language models, providing strong support for research in visual-language tasks.