
Microsoft Releases NVIDIA RTX Graphics Cards with 5x Faster AI Inference!
-
At the ongoing Microsoft Ignite global technology conference, Microsoft unveiled a series of new AI-optimized models and development tools to help developers better harness hardware performance and expand AI applications.
For NVIDIA, which currently dominates the AI field, Microsoft has delivered a significant gift. Whether it's the TensorRT-LLM wrapper interface for OpenAI Chat API, the performance improvements in RTX drivers like DirectML for Llama 2, or other popular large language models (LLMs), all can achieve better acceleration and application on NVIDIA hardware.
Among these, TensorRT-LLM is a library designed to accelerate LLM inference, significantly boosting AI inference performance. It is continuously updated to support more language models and is open-source.
In October, NVIDIA also released TensorRT-LLM for Windows. On desktops and laptops equipped with RTX 30/40 series GPUs, as long as the VRAM is no less than 8GB, users can more easily handle demanding AI workloads.
Now, Tensor RT-LLM for Windows can be compatible with OpenAI's widely popular chat API through a new wrapper interface, allowing various related applications to run locally without connecting to the cloud. This helps preserve private and proprietary data on PCs and prevents privacy leaks.
Any large language model optimized for TensorRT-LLM can work with this wrapper interface, including Llama 2, Mistral, NV LLM, and more.
For developers, there's no need for cumbersome code rewriting or porting. Just modify one or two lines of code to enable AI applications to execute quickly locally.
The TensorRT-LLM v0.6.0 update coming at the end of this month will bring up to 5x inference performance improvement on RTX GPUs, supporting more popular LLMs including the new 7B-parameter Mistral and 8B-parameter Nemotron-3, enabling desktops and laptops to run LLMs locally anytime with speed and accuracy.
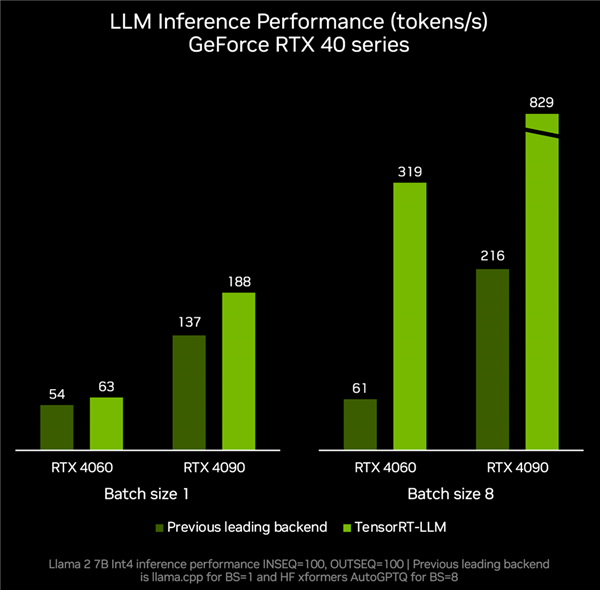
According to actual test data, RTX 4060 GPU with TensorRT-LLM can achieve 319 tokens per second in inference performance, which is 4.2x faster than other backends' 61 tokens per second.
The RTX 4090 can accelerate from tokens per second to 829 tokens per second, achieving a 2.8x performance improvement.
With powerful hardware performance, a rich development ecosystem, and broad application scenarios, NVIDIA RTX is becoming an indispensable assistant for local AI processing. The increasing optimizations, models, and resources are accelerating the adoption of AI features and applications across hundreds of millions of RTX PCs.
Currently, over 400 partners have released AI applications and games that support RTX GPU acceleration. As model usability continues to improve, we can expect to see more AIGC features emerging on Windows PC platforms.