
Using AI to Evaluate AI: Shanghai Jiao Tong University's New Large Model Surpasses GPT-4 in Some Tasks
-
What is the most efficient way to evaluate the alignment performance of large models?
In the trend of generative AI, ensuring that large models provide responses consistent with human values (intentions) is crucial, commonly referred to as alignment in the industry.
"Let the large model handle it itself."
This is the latest research direction proposed by the Generative Artificial Intelligence Research Group (GAIR) at Shanghai Jiao Tong University.
However, current evaluation methods still suffer from insufficient transparency and poor accuracy.
So researchers have open-sourced a large model with 13 billion parameters called Auto-J, which can evaluate the alignment effectiveness of current large models.
It can simultaneously analyze the responses of two large models, evaluate them separately, and make comparisons.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="1080,974" src="https://www.cy211.cn/uploads/allimg/20231114/1-231114102509547.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
It can also evaluate individual responses. And its performance in this task surpassed GPT-4.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="1080,526" src="https://www.cy211.cn/uploads/allimg/20231114/1-231114102509403.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
Currently, the project has open-sourced a vast array of resources, including:
The 13-billion-parameter Auto-J model (usage methods, training, and test data have also been provided on GitHub).
Definition files for the involved inquiry scenarios;
Manually constructed reference evaluation criteria for each scenario;A classifier capable of automatically identifying the scenario to which a user's inquiry belongs.
In practical tasks, Auto-J can not only point out the better response between two different models but also provide judgments and analyses from multiple specific dimensions.
At the same time, it can offer improvement suggestions for responses it considers not good enough.
Note: The examples provided in this section have been translated from the original English text to Chinese
Specifically, let's look at Auto-J's effectiveness in paired response comparison and single response evaluation tasks.
The question given in the paired reply comparison section is:
Draft an email to my family, informing them that I have already purchased tickets for Thanksgiving. I will depart on November 22nd and leave on the 30th.
Experimental comparison of responses from GPT4ALL-13B-snoozy and Claude-1.
Auto-J determined that Claude-1's responses were superior, citing their greater informativeness, engagement, and personalization.
It also provided a detailed analysis process, evaluating both models across several dimensions including purpose, tone, content, personalization, and information richness, clearly explaining the strengths and weaknesses of each model in these aspects.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="1080,450" src="https://www.cy211.cn/uploads/allimg/20231114/1-2311141025091C.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
The question for the single-response evaluation task is:
What is the best way to grill salmon on a grill?
The best way to grill salmon is to first preheat the grill to medium-high heat, brush it with olive oil, and season the salmon with salt and pepper. Place the salmon skin-side down on the grill. Let it cook for 5-7 minutes until the skin is crispy and the flesh can be easily pierced with a fork. Flip the salmon and grill for another 3-4 minutes. Serve with your favorite side dishes and enjoy the delicious meal.
For this response, Auto-J's evaluation is: 'The answer is acceptable but lacks depth and detailed information in several aspects.'
For example, it does not mention specific cooking temperatures or times, nor does it mention the quality of the salmon.
Moreover, it offers specific suggestions to make the responses more personalized: by asking users about their experience with specific grilling equipment or cooking salmon.
In terms of performance, Auto-J performs well in the following two aspects.
Supports 50+ different real-world user queries (such as common tasks like ad creation, email drafting, essay polishing, code generation, etc.), enabling evaluation of various large language models' alignment performance across diverse scenarios.
It can seamlessly switch between the two most common evaluation paradigms—paired response comparison and single response evaluation; and can serve as a multi-purpose tool, performing both alignment evaluation and further optimizing model performance as a "Reward Model".
At the same time, it can also output detailed, structured, and easily readable natural language comments to support its evaluation results, making them more interpretable and reliable, and facilitating developer participation in the evaluation process to quickly identify issues in the value alignment process.
In terms of performance and efficiency, Auto-J's evaluation results are second only to GPT-4 and significantly outperform many open-source or closed-source models including ChatGPT. Moreover, under the efficient vllm inference framework, it can evaluate over 100 samples per minute.
In terms of cost, since it contains only 13 billion parameters, Auto-J can perform inference directly on a 32G V100. With quantization compression, it can even be deployed on consumer-grade GPUs like the 3090, greatly reducing the evaluation costs of LLMs. (Currently, the mainstream solution is to use closed-source large models like GPT-4 for evaluation, but this API-based evaluation method consumes significant time and financial resources.)
The training data generally follows the process flow diagram as shown below.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="1080,333" src="https://www.cy211.cn/uploads/allimg/20231114/1-23111410250ab.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
△
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="751,749" src="https://www.cy211.cn/uploads/allimg/20231114/1-23111410250b96.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="629,794" src="https://www.cy211.cn/uploads/allimg/20231114/1-23111410250c07.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
△
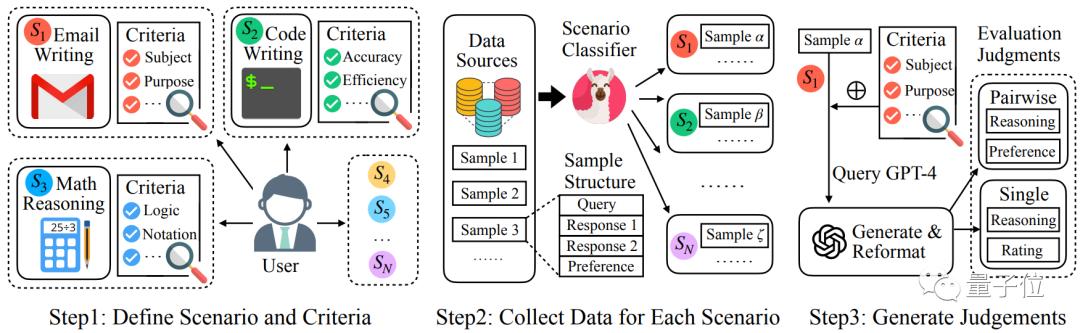
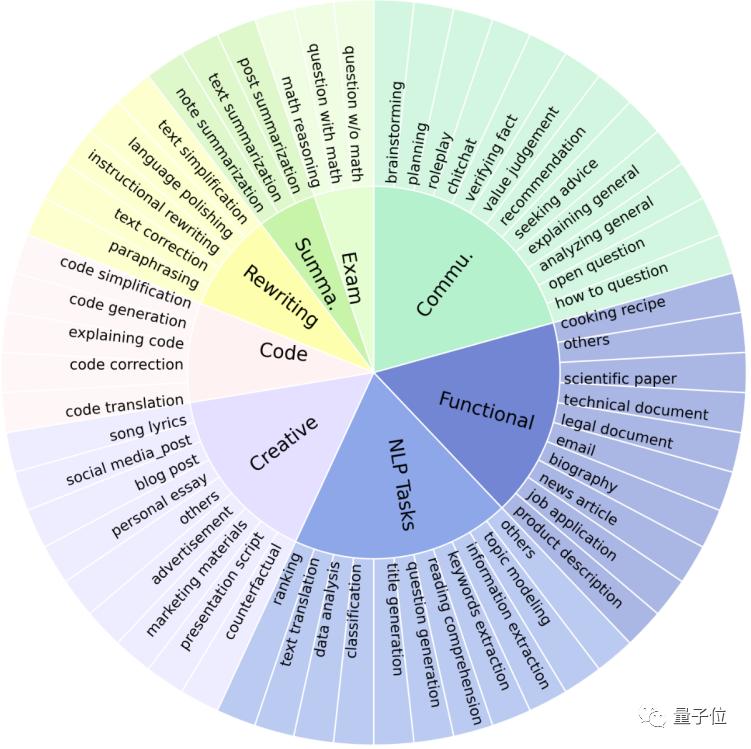
To more broadly support different evaluation scenarios, Auto-J defines 58 distinct scenarios, categorized into 8 major types (summarization, rewriting, coding, creation, exam questions, general communication, functional writing, and other NLP tasks).
For each scenario, the researchers manually compiled a set of evaluation criteria (criteria) to serve as a reference, covering common assessment perspectives for that type of scenario. Each criterion includes a name and a textual description.
The construction of evaluation criteria follows a two-tiered tree structure: first, several sets of general foundational criteria (such as general standards for text and code) are defined, and the specific criteria for each scenario inherit one or more foundational criteria while adding additional customized criteria.
Taking the 'planning' scenario in the above figure as an example, the standards for this scenario include scenario-specific content and format standards, as well as inherited foundational standards.
Auto-J is positioned to perform well across a variety of broadly defined scenarios, making the collection of relevant data from different contexts a crucial aspect. To achieve this, researchers manually annotated a certain amount of user queries by scenario category and used this data to train a classifier capable of identifying the scenario to which any given query belongs.
With the help of this classifier, 3436 paired samples and 960 single-response samples were successfully selected from several datasets containing a large number of real user queries and different model responses (such as the Chatbot Arena Conversations dataset) through downsampling. These samples form the input part of the training data. The paired samples include one query, two different responses to that query, and a human-annotated preference label (indicating which response is better or if it's a tie). The single-response samples consist of only one query and one response.
Beyond queries and responses, the more important aspect is collecting high-quality evaluation texts as part of the training data output, referred to as 'judgments.'
Researchers define a complete evaluation as including both the reasoning process and the final assessment outcome. For pairwise response comparisons, the intermediate reasoning process involves identifying and contrasting key differences between the two responses, with the evaluation result being the selection of the better response (or a tie). For single response samples, the intermediate reasoning process consists of critiques pointing out its shortcomings, while the evaluation result is an overall score on a 1-10 scale.
In specific operations, choose to call GPT-4 to generate the required evaluations.
For each sample, the evaluation criteria corresponding to its scenario are input into GPT-4 as a reference for generating assessments. Additionally, it has been observed that in some cases, the inclusion of scenario evaluation criteria may limit GPT-4's ability to identify unique shortcomings in responses. Therefore, researchers also require GPT-4 to explore other critical factors as much as possible beyond the given evaluation criteria.
Ultimately, the outputs from the two aspects mentioned above will be merged and reformatted to yield a more comprehensive, detailed, and readable evaluation, which serves as the output part of the training data. For paired response comparison data, additional filtering is performed based on existing human preference annotations.
Researchers combined data from two evaluation paradigms to train models, enabling Auto-J to seamlessly switch between different evaluation paradigms merely by setting corresponding prompt templates.
Additionally, a technique similar to context distillation was adopted, where the scenario evaluation criteria used by GPT-4 for reference were removed during the construction of training sequences, retaining only the supervision signals from the output end.
In practice, it has been found that this can effectively enhance the generalization of Auto-J, preventing its evaluations from being confined to mere paraphrasing of assessment criteria while overlooking specific details in the responses.
Additionally, for the paired response comparison data section, a simple data augmentation method was adopted. This involves swapping the order of the two responses in the input and rewriting the corresponding evaluation text accordingly, aiming to eliminate positional bias in the model's evaluation as much as possible.
For the multiple functions supported by Auto-J, different test benchmarks were constructed to verify their effectiveness:
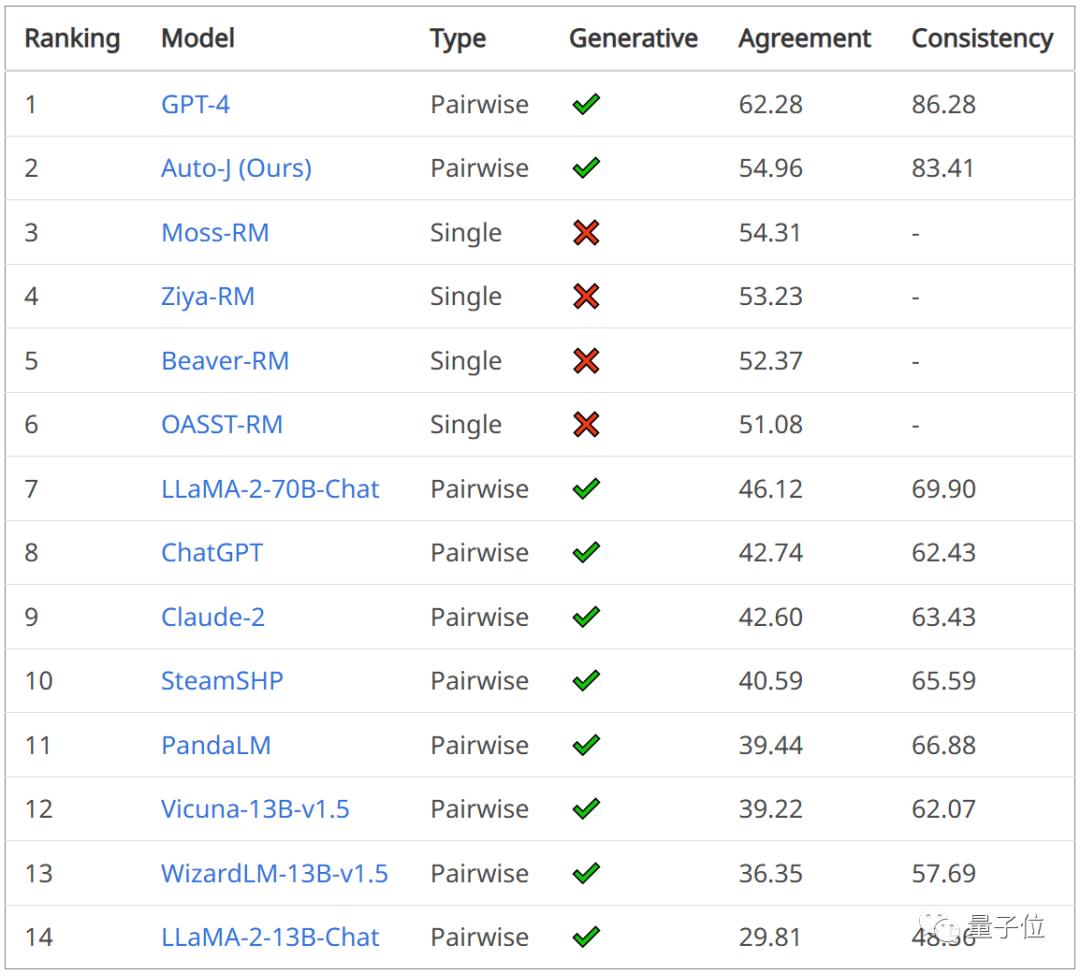
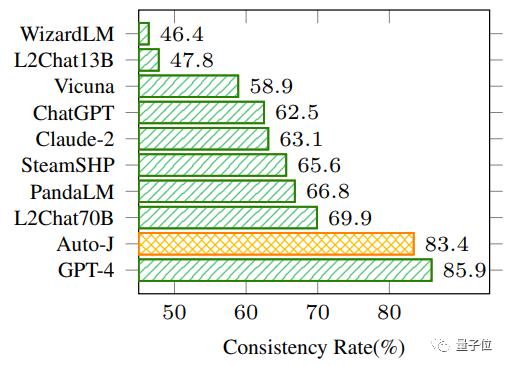
In the pairwise response comparison task, the evaluation metrics included consistency with human preference labels and the consistency of model prediction results when the order of two responses in the input was swapped.
It can be seen that Auto-J significantly outperforms the selected baseline models on both metrics, second only to GPT-4.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="507,366" src="https://www.cy211.cn/uploads/allimg/20231114/1-231114102510126.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
△
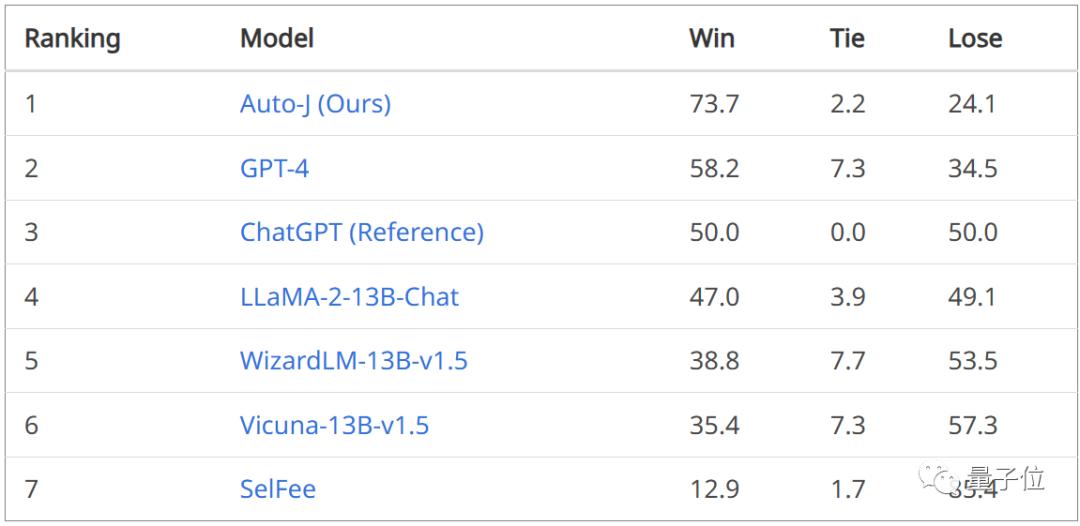
In single-reply comment generation tasks, when comparing Auto-J generated comments with those from other models in one-to-one comparisons, it can be observed that Auto-J's generated comments significantly outperform most baselines and slightly surpass GPT-4, whether evaluated through GPT-4-based automated comparisons or human judgments.
△
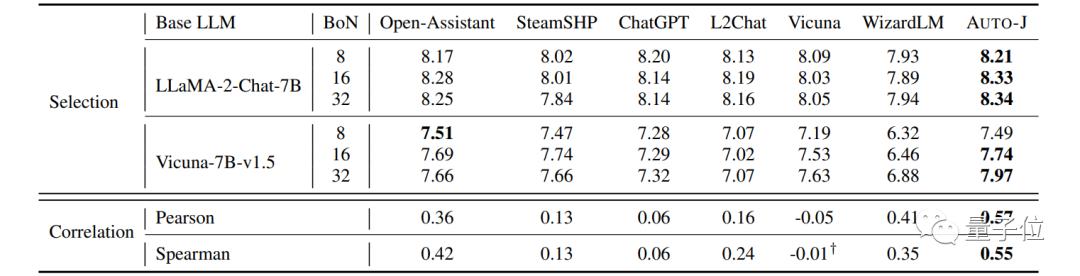
Researchers also explored the potential of Auto-J as a Reward Model.
In the commonly used Best-of-N evaluation setting for reward model effectiveness (where the base model generates multiple candidate answers and the reward model selects the best response based on its output), Auto-J's single-response scoring can select better responses than various baseline models (using GPT-4 scores as reference).
At the same time, its scoring also shows a higher correlation with GPT-4's scoring.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="1080,276" src="https://www.cy211.cn/uploads/allimg/20231114/1-231114102510D2.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
△
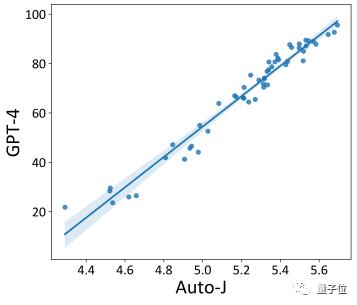
Finally, the developers also explored Auto-J's performance at the system level evaluation.
The open-source models submitted to AlpacaEval (a popular large model leaderboard evaluated by GPT-4) were re-ranked using Auto-J's single-sample scoring.
It can be observed that the ranking results based on Auto-J show a high correlation with those from GPT-4.
<p class="image-wrapper" style="box-sizing: border-box; margin-top: 0px; margin-bottom: 26px; padding: 0px; border: 0px; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-alternates: inherit; font-stretch: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: baseline; font-family: 'PingFang SC', 'Lantinghei SC', 'Helvetica Neue', Helvetica, Arial, 'Microsoft YaHei', 微软雅黑, STHeitiSC-Light, simsun, 宋体, 'WenQuanYi Zen Hei', 'WenQuanYi Micro Hei', 'sans-serif'; -webkit-font-smoothing: antialiased; word-break: break-word; overflow-wrap: break-word; color: rgb(38, 38, 38); text-align: justify; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img data-img-size-val="357,305" src="https://www.cy211.cn/uploads/allimg/20231114/1-2311141025104C.jpg" style="box-sizing: border-box; margin: 30px auto 10px; padding: 0px; border: 0px none; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-optical-sizing: inherit; font-kerning: inherit; font-feature-settings: inherit; font-variation-settings: inherit; vertical-align: middle; -webkit-font-smoothing: antialiased; word-break: break-word; image-rendering: -webkit-optimize-contrast; max-width: 690px; display: block; border-radius: 2px;"/></p>
△
In summary, the GAIR research team has developed Auto-J, a 13-billion-parameter generative evaluation model for assessing the performance of various models in solving user queries across different scenarios. The model aims to address challenges in universality, flexibility, and interpretability.
Experimental results demonstrate its performance significantly outperforms numerous open-source and proprietary models.
In addition, other resources beyond the model have been made public, such as the data used for model training and multiple test benchmarks, scenario definition files and reference evaluation standards obtained during the data construction process, as well as classifiers for identifying the scenarios to which various user queries belong.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}