
AI Image Generation Model LCMs: A New Approach for Rapid High-Quality Image Generation
-
In the latest AI models and research fields, a new technology called Latent Consistency Models (LCMs) is rapidly advancing text-to-image artificial intelligence. Compared to traditional Latent Diffusion Models (LDMs), LCMs excel in generating detailed and creative images while requiring only 1-4 steps instead of hundreds. This innovation represents a significant leap forward for text-to-image AI.
<p class="article-content__img" style="margin-top: 0px; margin-bottom: 28px; padding: 0px; box-sizing: border-box; outline: 0px; border-width: 0px; border-style: solid; border-color: rgb(229, 231, 235); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; line-height: 32px; text-align: center; color: rgb(59, 59, 59); word-break: break-word; font-family: 'PingFang SC', 'Microsoft YaHei', Helvetica, 'Hiragino Sans GB', 'WenQuanYi Micro Hei', sans-serif; letter-spacing: 0.5px; display: flex; -webkit-box-align: center; align-items: center; -webkit-box-pack: center; justify-content: center; flex-direction: column; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img src="https://www.cy211.cn/uploads/allimg/20231113/1-231113124202164.png" title="image.png" alt="image.png" style="margin: 0px auto; padding: 0px; box-sizing: border-box; outline: 0px; border: 1px solid rgb(238, 238, 238); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; max-width: 700px; background: url('../img/bglogo2.svg') center center no-repeat rgb(247, 248, 249); box-shadow: rgba(27, 95, 160, 0.1) 0px 1px 3px; display: inline-block;"/></p>
The breakthrough of LCMs lies in drastically reducing the number of steps required to generate images. Compared to the time-consuming generation process of LDMs, which requires hundreds of steps, LCMs achieve similar quality levels with just 1-4 steps. This efficiency is achieved by refining pre-trained LDMs into a more simplified form, greatly reducing the demand for computational resources and time.
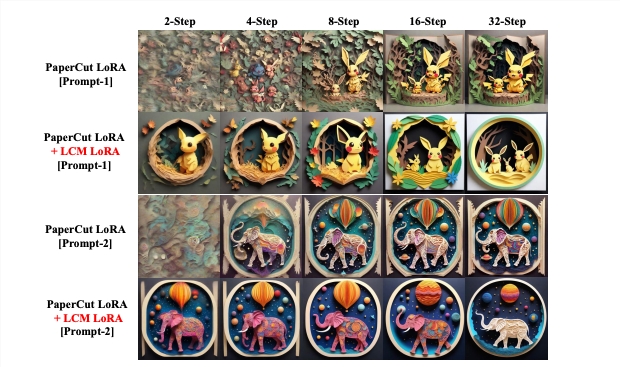
The paper introducing the LCM model also mentions an innovation called LCM-LoRA, a universal stable diffusion acceleration module. This module can be directly inserted into various fine-tuned stable diffusion models without requiring additional training. It serves as a potential tool in AI-driven image generation, capable of accelerating diverse image generation tasks.
In the paper, the research team adopted an ingenious method called 'distillation' to efficiently train Latent Consistency Models (LCMs). They first trained a standard Latent Diffusion Model (LDM) on a text-image paired dataset, then used the newly generated training data from it to train the Latent Consistency Model (LCM). This distillation process enables LCMs to learn from LDM's capabilities without requiring training from scratch on massive datasets. The efficiency of this approach is demonstrated by the researchers successfully training high-quality LCMs in approximately 32 hours using just a single GPU, significantly faster than previous methods.
The research results showcase significant progress in image generation AI through LCMs. LCMs are capable of creating high-quality 512x512 images in just 4 steps, representing a substantial improvement compared to Latent Diffusion Models (LDMs) that require hundreds of steps. These models not only handle smaller images with ease but also excel in generating larger 1024x1024 images, demonstrating their ability to adapt to larger neural network models.
<p class="article-content__img" style="margin-top: 0px; margin-bottom: 28px; padding: 0px; box-sizing: border-box; outline: 0px; border-width: 0px; border-style: solid; border-color: rgb(229, 231, 235); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; line-height: 32px; text-align: center; color: rgb(59, 59, 59); word-break: break-word; font-family: 'PingFang SC', 'Microsoft YaHei', Helvetica, 'Hiragino Sans GB', 'WenQuanYi Micro Hei', sans-serif; letter-spacing: 0.5px; display: flex; -webkit-box-align: center; align-items: center; -webkit-box-pack: center; justify-content: center; flex-direction: column; text-wrap: wrap; background-color: rgb(255, 255, 255);"><img src="https://www.cy211.cn/uploads/allimg/20231113/1-2311131242035C.png" title="image.png" alt="image.png" style="margin: 0px auto; padding: 0px; box-sizing: border-box; outline: 0px; border: 1px solid rgb(238, 238, 238); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; max-width: 700px; background: url('../img/bglogo2.svg') center center no-repeat rgb(247, 248, 249); box-shadow: rgba(27, 95, 160, 0.1) 0px 1px 3px; display: inline-block;"/></p>
However, a major limitation of current LCMs is the two-stage training process, which first trains an LDM and then uses it to train the LCM. Future research may explore more direct training methods for LCMs, potentially avoiding the use of LDMs. Additionally, the paper mainly discusses unconditional image generation, and more work may be needed for conditional generation tasks such as text-to-image synthesis.
Latent Consistency Models represent a significant advancement in fast, high-quality text-to-image generation. These models are capable of producing results comparable to slower LDMs in just 1-4 steps, promising to revolutionize the application of text-to-image models in practical scenarios.
Although there are still some limitations, particularly in the training process and the scope of generation tasks, LCMs mark an important step forward in neural network-based image generation. The LCM-LoRA model combined with LoRA provides a general solution for efficiently generating high-quality, style-specific images, with extensive practical application potential that could bring disruptive innovations from digital art to automated content creation.
{kind=link}
{kind=link}