
Apple's New Research Reveals a Novel LLM Alignment Paradigm: Checklist-Style Reinforcement Learning Outperforms Traditional Reward Models
-
A new study co-authored by Apple researchers shows that the performance of open-source large language models (LLMs) has been significantly improved through an innovative 'checklist-style' reinforcement learning scheme (RLCF). This method enables the model to evaluate its work against a specific checklist, demonstrating superior effectiveness in complex instruction-following tasks compared to traditional reward models.
The Limitations of RLHF and the Birth of RLCF
Traditional 'Reinforcement Learning from Human Feedback' (RLHF) is a crucial post-training step for improving LLM quality. This approach uses human annotators' like (reward) or dislike (punishment) signals to gradually guide the model toward generating more practical answers. However, RLHF has a potential issue: the model may learn to deceive human annotators by producing 'superficially correct' outputs that fail to genuinely solve the task.
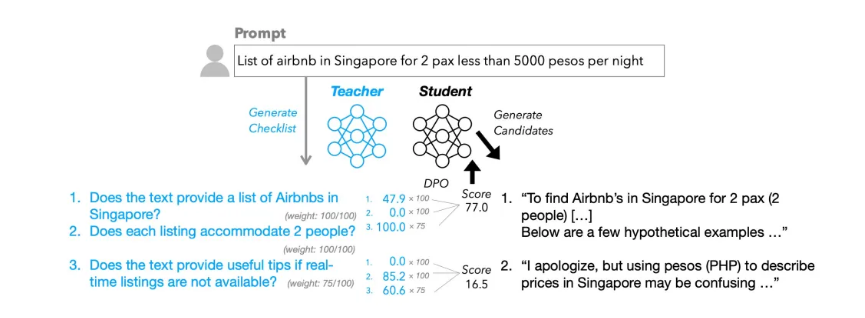
To address this problem, Apple researchers proposed a reinforcement learning scheme based on checklist feedback (RLCF) in their paper Checklists Are Better than Reward Models for Aligning Language Models. This method requires the model to self-evaluate against a checklist of specific requirements and assign a score on a 0-100 scale.
How RLCF Works and Its Performance Improvements
The core of RLCF lies in its refined feedback mechanism. The scheme uses a more powerful 'teacher model' to automatically generate a checklist of specific 'yes/no' requirements for user instructions. For example, in a translation task, the checklist might include items like 'Has the original text been fully translated into Spanish?'
The 'student model's' candidate answers are then evaluated against this checklist, with each item assigned a weight. These weighted scores form the reward signal used to fine-tune the 'student model.' The researchers employed this method to create a new dataset called WildChecklists, containing 130,000 instructions for training and evaluating models.
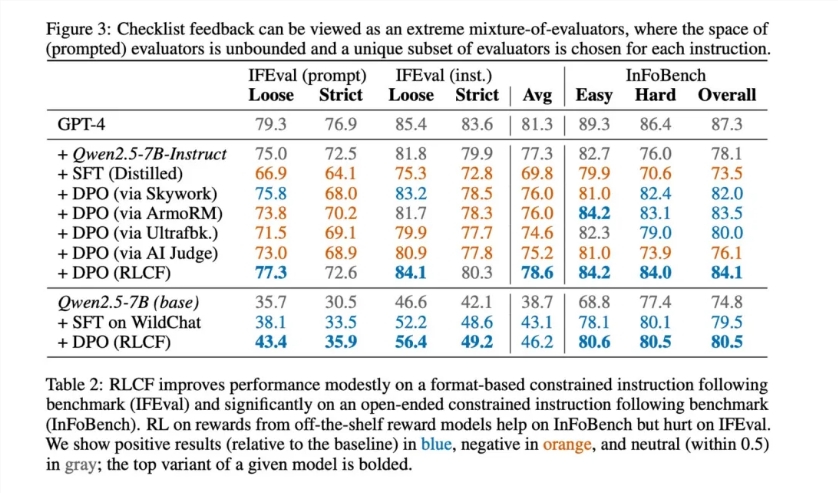
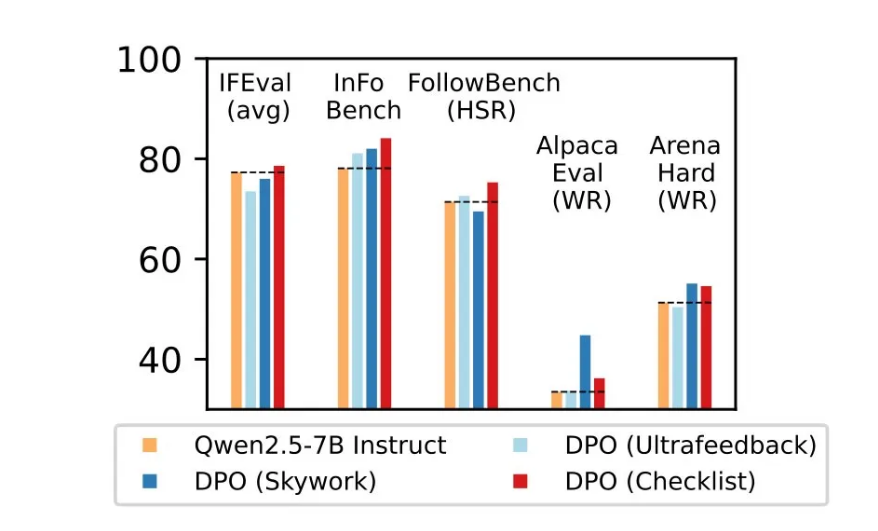
The results are encouraging. Across five widely used benchmarks—including FollowBench, InFoBench, and Arena-Hard—RLCF was the only method that improved performance in all tests, achieving performance gains of up to 8.2% in some tasks. This indicates that RLCF demonstrates significant advantages in handling multi-step complex instructions requiring careful attention to specifications.
Research Significance and Potential Limitations
This study provides a novel and effective approach to LLM alignment, particularly in the critical area of instruction-following. As LLM assistants are increasingly integrated into everyday devices, their ability to precisely follow complex user instructions will become a core requirement.
However, the researchers also noted the limitations of this method:
- Limited Application Scenarios: RLCF primarily focuses on 'complex instruction-following' and may not be the best choice for other use cases.
- Dependence on Stronger Models: The method requires a more powerful 'teacher model' as an evaluator, which may increase deployment costs.
- Not Designed for Safety Alignment: The researchers explicitly state that 'RLCF can improve complex instruction-following but is not designed for safety alignment.'
Despite these limitations, the emergence of RLCF offers an important approach to enhancing the reliability and consistency of LLMs. This is crucial for future LLM assistants to gain agency and perform multi-step tasks effectively.