
Apple Releases Adapted SlowFast-LLaVA Model: Long-Form Video Understanding Performance Surpasses Larger-Scale Models
-
According to foreign media reports, Apple's research team recently released an adapted version of the SlowFast-LLaVA model, which demonstrates outstanding performance in long-form video analysis and comprehension tasks, even surpassing models with larger parameter scales. This breakthrough provides an efficient new solution for long-form video content analysis.
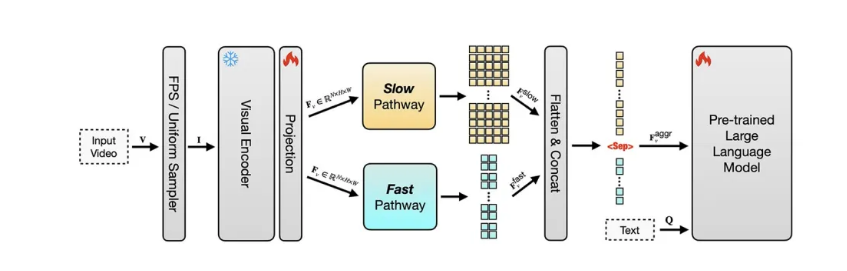
The model's core advantage lies in its dual-stream architecture, which effectively addresses issues of information redundancy and context window overflow in traditional frame-by-frame processing. The slow stream (Slow) captures static details and background information at a low frame rate, while the fast stream (Fast) tracks rapid changes in motion at a high frame rate. This collaborative working mode significantly optimizes video processing efficiency.
In long-form video benchmark tests, SlowFast-LLaVA demonstrated exceptional performance. Its 1-billion, 3-billion, and 7-billion parameter versions all achieved excellent results. For example, the 1-billion parameter model scored 56.6 on the General VideoQA task in LongVideoBench, while the 7-billion parameter version achieved a high score of 71.5 on the Long-Form Video Understanding task. Beyond video comprehension, the model also performed well in knowledge reasoning and OCR tasks related to image understanding.
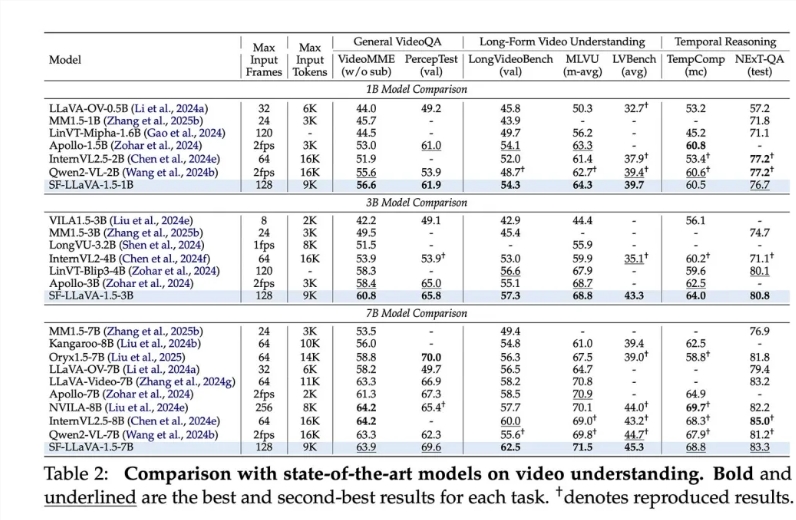
Despite its outstanding performance, the model currently has certain limitations, such as an input frame length capped at 128 frames, which may lead to the omission of key information. Apple's team stated that they will continue to explore memory optimization techniques to enhance the model's performance.
SlowFast-LLaVA was trained on publicly available datasets and has been open-sourced, providing the broader AI community with new ideas and efficient tools for long-form video understanding.