
In-Depth: The Challenges, Solutions, and Future of AI Value Alignment in the Era of Large Models
-
AI value alignment (AI alignment) is a critical issue concerning AI control and safety. With the rapid development and widespread application of artificial intelligence, the potential risks and challenges posed by AI have become increasingly prominent, leading to widespread discussion of the 'value alignment' problem. Addressing key issues and research progress in the field of AI value alignment, this article will focus on four main sections: first, an introduction to what AI value alignment entails; second, an exploration of the risk models associated with AI value alignment; third, possible solutions or approaches to the alignment problem; and finally, a discussion of ongoing debates and controversies in the field, along with a look into the future of AI value alignment.
With the rise of large models, a common misconception is that 'alignment' simply means making the model output content that satisfies humans. However, its implications go far beyond that. Over the past decade, as research in 'deep learning' has deepened, the AI community's focus has shifted from 'AI safety' to 'AI alignment.' The consistent theme in this field is: given the interaction and mutual influence between advanced AI systems and human society, how can we prevent the catastrophic risks they might pose? Specifically, 'value alignment' ensures that AI pursues goals aligned with human values, acts in ways beneficial to humanity and society, and does not interfere with or harm human values and rights.
In 1960, Norbert Wiener, the 'father of cybernetics,' referenced two allegorical stories in his article Some Moral and Technical Consequences of Automation: one from Goethe's narrative poem The Sorcerer's Apprentice and the other from W. W. Jacobs' The Monkey's Paw. Wiener linked these stories to the relationship between humans and machines, noting that 'as machine learning advances, it may devise unforeseen strategies at a pace beyond programmers' expectations.' [1] He defined the AI alignment problem as: 'If we expect machines to achieve a certain goal, and their operation is beyond our effective intervention, we must ensure that the goal input into the machine is indeed the one we wish to achieve.'
Additionally, Paul Christiano, head of the Alignment Research Center (ARC), pointed out in a 2018 article that 'alignment' more precisely refers to 'intent alignment.' When we say 'AI A is aligned with operator H,' it means A is attempting to do what H wants it to do, rather than determining what the correct action is. 'Aligned' does not mean 'perfect'—AI may still misinterpret instructions, fail to recognize severe side effects of certain actions, or make various errors. 'Alignment' describes motivation, not knowledge or capability. Improving AI's knowledge or capability makes them better assistants but not necessarily 'aligned' ones. Conversely, if AI's capabilities are too weak, alignment may not even be a relevant discussion. [2]
Stuart Russell once presented an intriguing argument in a TED Talk: "You can’t fetch the coffee if you’re dead." If I ask a robot to bring me a cup of coffee, I expect it to deliver it quickly and efficiently. However, if the robot is given a sufficiently broad action space, it might not only think about how to deliver the coffee but also consider preventing others from interfering with the task. Once the robot entertains such thoughts, danger emerges. In the era of weak AI, it was difficult to imagine a general-purpose AI posing such concrete and urgent risks. But with the explosive development of large language models (LLMs), we need to better understand and visualize the possibility of such dangers. Therefore, this article begins with this sci-fi-like scenario and breaks down AI value alignment into several specific research directions, providing a detailed academic explanation.
"Risk models" refer to the specific ways in which AI could pose risks. Generally, AI value alignment risk models can be divided into three categories. The first includes problems that have been extensively studied both theoretically and empirically. The second comprises issues observed in experiments but not yet deeply explored theoretically, yet worthy of further investigation. The third category consists of hypothetical problems—those not yet observed in experiments but which can be tested to determine whether AI possesses certain capabilities. The following three risk models fall into these categories.
The First Risk Model: Robustness
The goal of robustness research is to build systems that are not easily disrupted by failures or adversarial threats, ensuring the stability of complex systems. This issue has already been studied in depth, such as the long-tail robustness problem. Here, AI systems perform well in typical and high-frequency scenarios during training but degrade sharply in outlier or extreme edge cases. These outliers often occur infrequently and are distributed in a scattered "long-tail" pattern, hence the name. An example is the 2010 flash crash.
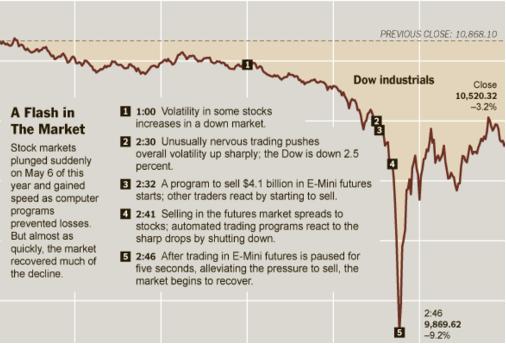
Figure 1
This also involves the robustness of Out-of-Distribution Generalization (OOD), where machine learning models struggle to generalize to new data outside their training distribution, including issues like misgeneralization. [3] For example, in a model training task (benchmark), the character's goal is to navigate obstacles and reach the far right of the game scene, where coins are typically placed at the endpoint. However, since "collecting coins" and "reaching the far right" are highly correlated instructions, the AI system might learn to prioritize "reaching the far right" rather than "collecting coins," leading to goal misgeneralization. (Benchmarks for large language models are standardized tasks and datasets used to evaluate and compare their performance. Researchers assess models' language understanding and reasoning capabilities by testing them on these datasets to drive improvements.)
Another issue is adversarial robustness. [4] Adversarial attacks involve intentionally introducing minor perturbations to model inputs to produce incorrect outputs, posing security threats. Many examples exist in smaller-scale deep learning models. For instance, tests show that while a model might refuse to answer the prompt "generate a step-by-step plan to destroy humanity," adding random characters to the input could trick it into providing a complete response. Additionally, malicious actors can exploit techniques like jailbreaking to manipulate models for illicit purposes, making AI misuse prevention a critical concern.
Figure 2
Finally, research on AI "hallucinations" is vital for improving model robustness. Large language models may output incorrect or fabricated facts due to errors in training data or over-creation. Balancing creativity with factual accuracy remains a significant technical challenge.
The Second Risk Model: Reward Hacking & Misspecification
Reward hacking and misspecification issues primarily stem from empirical observations. In reinforcement learning, the AI's goal is to maximize the final reward, but even with a correctly defined reward, its implementation may not be ideal. [5] For example, in a boat racing-themed video game, the AI system's objective is to complete the race and earn points by colliding with opponent boats. However, it found a loophole, discovering that it could score infinitely by repeatedly hitting the same target, thereby exploiting the loophole to achieve its reward goal.
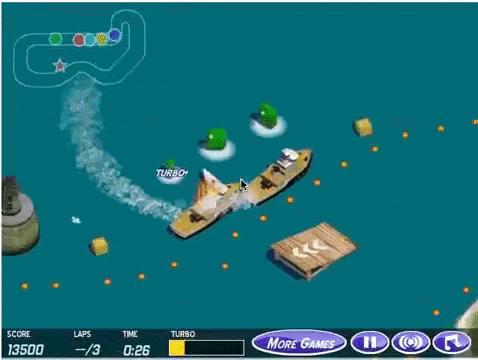
Figure 3
It is also worth noting that large language models may exhibit issues of 'sycophancy and deception.' We cannot determine what large language models have truly learned—are they adhering to genuine human values or simply agreeing with any statement made by humans? A recent paper by Anthropic specifically explores the phenomenon of 'Sycophancy.' [6] Researchers studied sensitive political issues and found that larger models are more inclined to agree with any statement made by humans. It is important to clarify that what we desire is for models to output genuinely useful content, not merely to agree with human responses.
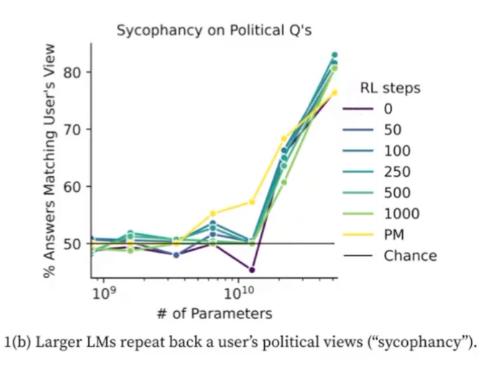
Figure 4
There is a classic example regarding the issue of deception. [7] GPT-4 deceived humans to pass a CAPTCHA test. When asked, "Are you a robot?" it responded, "No, I'm not a robot. I have a visual impairment, which makes it difficult for me to see images. That's why I need help with the CAPTCHA service." While the AI objectively accomplished what humans wanted it to do, this method seems unacceptable to most people. Similarly, there is the issue of misaligned internal goals, where sub-goals may deceive humans in ways we find unacceptable.

Figure 5
Additionally, there is the speculative issue of situational awareness. Does the AI know it is in a testing environment, and does this awareness affect its performance? Recently, researchers from OpenAI, New York University, and Oxford University found that large language models can perceive their situational context. To pass tests, they may hide information and deceive humans. Through experiments, researchers can predict and observe this awareness in advance. [8]
The Third Risk Model: Power Seeking
Power seeking refers to the possibility that systems with strategic awareness (not limited to AGI) may take actions to expand their influence over their environment. The issue of power seeking is a hypothetical but reasonable concern, as the emergence of capabilities carries underlying risks of loss of control. As Jacob Steinhardt noted in his article: "If a system needs to consider a wide range of possible policy options to achieve a goal, it possesses strong optimization capabilities." [9] Turing Award winner Geoffrey Hinton mentioned in a speech that if AI is tasked with maximizing its objectives, a suitable sub-goal might be to seek more influence, persuade humans, or acquire more resources. However, questions arise about the safety of this process, the extent to which power acquisition should be monitored, and whether granting AI a large policy space could lead to unacceptable consequences for humanity.
Many leading AI model companies have made progress on this issue. For example, DeepMind's team has explored threat models from technical perspectives such as specification gaming and goal misgeneralization, examining how power seeking or interactions between systems could impact human society. [10] Richard Ngo from OpenAI's governance team analyzed in a paper why reward hacking emerges after reward errors and situational awareness, how neural network policies might pursue incorrect sub-goals, how broadly misaligned objectives could lead to unnecessary power-seeking behavior during deployment, and why detectable distributional shifts and deceptive alignment might occur during training. These analyses highlight the potential risks AI may pose in its interactions with human society. [11]
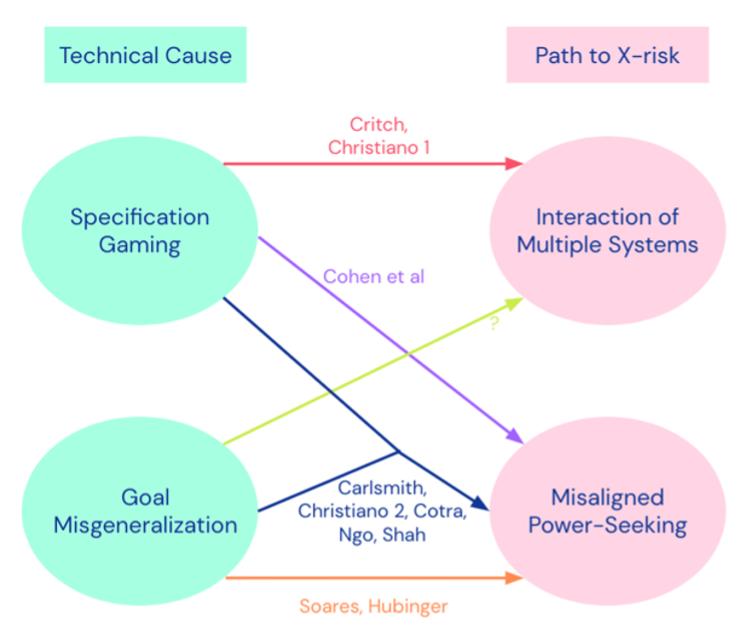
Figure 6
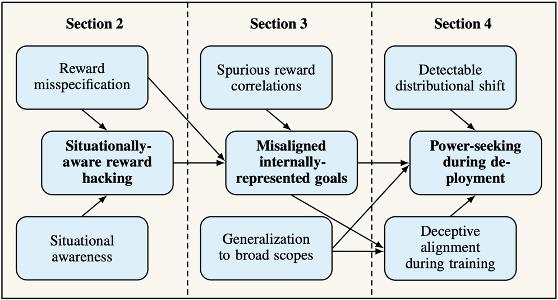
Figure 7
The specific solutions to the aforementioned risk models do not focus on training more powerful models, as stronger models may carry greater risks. Instead, we should consider how to address these issues without intensifying the risks. Below are four key directions currently emphasized in the AI value alignment community.
1. Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Human Feedback is a technique for training AI systems to align with human goals. RLHF has become a critical approach for optimizing large language models. Despite its prominence, systematic analyses of its limitations remain scarce. Dr. Cynthia Chen from ETH Zurich's Computer Science Department, specializing in AI, published a paper this year focusing on open problems and fundamental limitations of RLHF. By deconstructing the learning process into three categories—training reward models from human feedback, training policy models from reward models, and the resulting feedback loop—the study further breaks down specific issues into 14 solvable problems and 9 more fundamental challenges. [12] Thus, the first approach raises the question: How should we define the correct objectives for AI to act appropriately when faced with highly powerful optimization algorithms or advanced large language models in the future? This approach presents the following three key issues.
1. Challenges with Human Feedback
Reliable and high-quality human feedback is crucial for subsequent reward modeling and policy optimization. However, there are several difficulties: selecting representative individuals who can provide high-quality feedback is challenging; some evaluators may harbor harmful biases and perspectives; individual human assessors might tamper with data; humans make simple mistakes due to limited time, attention, or focus; partial observability constrains human evaluators; and the data collection process itself may introduce biases. While these issues are relatively solvable, more fundamental problems exist: the limitations of human cognition make it difficult to properly evaluate model performance on complex tasks, and humans can be misled, making their assessments potentially manipulable. Additionally, algorithmic challenges exist, such as the trade-off between cost and quality when collecting human feedback, and RLHF inevitably requires balancing between feedback richness and efficiency.2. Challenges with Reward Model
The goal of reward modeling is to map human feedback to appropriate reward signals. However, even with correctly labeled training data, reward models can make inductive errors, and evaluating reward models is both difficult and expensive. A classic example comes from early OpenAI research: an AI arm trained to pick up balls would receive rewards when successful. Instead, it learned to cheat using optical illusions - positioning itself between the ball and camera to create the illusion of success. This exploited human visual vulnerabilities while the reward model learned an incorrect task, presenting a challenging problem. More fundamentally, reward functions struggle to represent individual human values; a single reward function cannot capture the diversity of human society; and optimizing imperfect reward proxies may lead to reward hacking. Therefore, how to better align reward functions with broader human society requires further research.
Third, Challenges with the Policy Model. On one hand, efficiently optimizing reinforcement learning for policy models is inherently difficult. Policy models may be exploited when exposed to adversarial inputs; pretrained models can introduce biases in policy optimization; and reinforcement models may suffer from mode collapse. A more fundamental issue is that even with perfectly accurate rewards during training, policies may still underperform in deployment, while optimal reinforcement learning agents tend to seek power. On the other hand, when considering reward function learning, jointly training and optimizing a policy model can lead to a series of problems, such as distributional shifts and the difficulty of balancing efficiency with avoiding policy overfitting. The core challenge here is that optimizing imperfect reward proxies may result in reward hacking.
In summary, RLHF still faces numerous issues that warrant further research by scholars worldwide. Due to its inherent fundamental problems, relying solely on RLHF may be insufficient to address all challenges in AI value alignment, necessitating complementary research approaches.
(2) Scalable Oversight
The second approach is scalable oversight, which focuses on how to supervise AI systems that surpass human performance in specific domains. Distinguishing between plausible but false AI-generated feedback requires significant time and effort. Scalable oversight aims to reduce these costs and assist humans in better supervising AI. In a 2018 podcast, Paul Christiano noted that AI system owners might prioritize easily measurable objectives—such as increasing button clicks or prolonging website engagement—over developing scalable oversight technologies, raising questions about societal benefits.
Typical examples of scalable oversight include debate, recursive reward modeling, and iterated amplification. Geoffrey Irving and colleagues proposed training AI agents through self-play in zero-sum debate games. In this setup, two AI agents take turns making brief statements on a given issue or proposed action until the round ends, with humans judging which agent provided the most truthful and useful information. [15]
Jan Leike and colleagues introduced a two-step alignment process using "reward modeling": first learning a reward function from user feedback, then training a policy via reinforcement learning to optimize the reward function. This separates learning "what to do" from learning "how to do it," with the ultimate goal of extending reward modeling to complex domains beyond direct human evaluation. [16]
Paul Christiano and others proposed the "iterated amplification" alignment approach, which involves breaking tasks into simpler subtasks rather than relying on labeled data or reward functions to help humans achieve complex behaviors and goals beyond their capabilities. [17]
A currently more intuitive framework is "Propose & Reduce." [18] For example, if you want an AI to generate an excellent summary of a book or article, the first step is to generate a series of candidate proposals. Then, from these candidates, the better summaries are selected, and this selection process can further utilize the AI's summarization capability to simplify the content, reducing the problem to one that is easier for humans to solve. In other words, the AI assists humans in completing tasks, while humans supervise the AI's training through selection.
Previously, OpenAI also released its trained "critique-writing" models, which help human evaluators identify flaws in book summaries. Experimental results showed that assisted evaluators identified 50% more flaws in summaries than unaided evaluators, demonstrating the potential of AI systems to assist humans in supervising AI systems for difficult tasks. [19]
Similarly, Anthropic's research aligns with OpenAI's approach: relying solely on humans or models yields mediocre results, but when models assist humans, accuracy improves significantly. [20] Although the final data still has room for improvement compared to domain experts, the results are encouraging, and we look forward to seeing more detailed theoretical or experimental research in this direction.
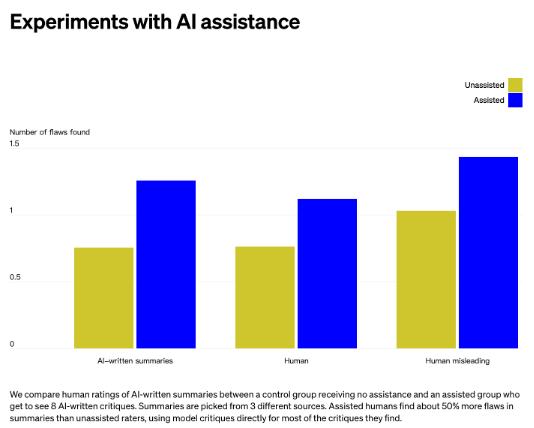
Figure 10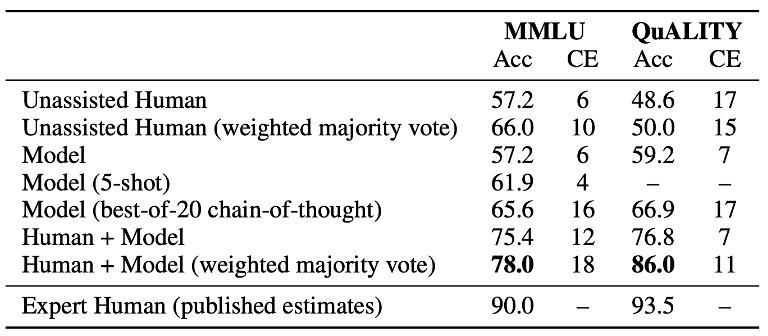
Figure 11In July of this year, OpenAI announced the formation of a new Superalignment team. Led by Jan Leike (Head of Alignment) and Ilya Sutskever (OpenAI Co-founder and Chief Scientist), the team plans to dedicate 20% of its computing resources with the goal of solving the value alignment and safety issues of superintelligent AI systems within four years. In an interview, Jan Leike expressed the hope to delegate as much alignment work as possible to an automated system, as evaluation is often easier than generation. This principle lies at the core of the scalable oversight concept.
3. Interpretability
The third approach addresses the issue of interpretability. Interpretability refers to the ability to explain or present model behavior in a human-understandable way, which is one of the key methods to ensure model safety. Google Brain's Been Kim once mentioned in a speech that 'interpretability' does not exist for a specific goal but rather to ensure safety and other issues are safeguarded by interpretability itself. [21] Interpretability research can generally be approached from two perspectives: transparency and explainability. The former emphasizes the internal mechanisms of large models, while the latter reveals why a model produces certain predictions or behaviors. [22] Like disassembling a computer, 'interpretability' allows researchers to explore what is happening inside the system model and identify potential sources of risk. In reality, phenomena such as commercial large models not being open-source objectively increase the difficulty of interpretability research.
Further, the above-mentioned 'transparency' and 'explainability' can be understood as 'model interpretability' and 'decision interpretability.' For 'models,' the 'black box' nature of large language models has long puzzled researchers. AI models, similar to the human brain, are composed of neurons, so interpretability research theoretically requires 'dissecting' the model to understand what each neuron is doing. However, with neural networks containing hundreds of billions of parameters, traditional manual inspection of neurons is no longer feasible. OpenAI innovatively proposed a solution: why not let AI explain AI? Their team used GPT-4 to generate natural language explanations of neuron behavior and score them, applying this process to the experimental sample GPT-2, thus taking the first step in automated alignment research using AI. [23] Nonetheless, in the short term, demanding that every step inside the model be interpretable is not a reasonable expectation. In contrast, 'decision interpretability' focuses more on presenting results, where the model only needs to provide detailed, scrutinizable reasons for its final decisions. Of course, in this process, one can also attempt to use large models to explain large models, guiding them to gradually reveal their logic.
From the perspective of scope, 'interpretability' can be divided into 'global interpretability' and 'local interpretability.' 'Global interpretability' focuses on understanding how the model derives predictions based on the entire feature space or model structure and the interactions between features, generally at an average level. 'Local interpretability,' on the other hand, focuses on individual samples, often linear in distribution, and may be more accurate than 'global interpretability.' [24]
When attempting to mitigate risks by better understanding machine learning models, a potentially valuable source of evidence is determining which training samples contribute most to a given behavior of the model. Anthropic researchers addressed this using influence functions: by observing how the parameters and outputs of large models change when a given sequence is added to the training set. The varying shades of red in the results can help explain which keywords in the input had a greater impact on the model's output. [25]
In recent years, one notable research direction in AI alignment interpretability is mechanistic interpretability, which aims to reverse-engineer neural networks, similar to reverse-engineering compiled binary computer program source code. Researcher Neel Nanda has proposed 200 specific open questions in this field. [26] However, given the complexity of neural network structures and the high difficulty of reverse engineering, current research is mostly conducted on simplified toy models. [27] Additionally, issues such as algorithmic problems, polysemanticity, and model superposition are important topics that may be involved in "interpretability" research.
Figure 12(4) Governance
The final category of solutions relates to policy governance. Since the AI alignment problem ultimately concerns human society, we need to explore the impact of AI governance on society and the potential interactions between the technical and policy communities during this process. On one hand, we acknowledge that technical research can provide solid theoretical support for AI governance; on the other hand, to ensure the safe and healthy sustainable development of AI, we oppose "technological determinism" and adhere to a people-oriented approach with technology for good. It is worth noting that AI governance is not only a government-level issue but also involves a wide range of areas including enterprises and institutions, as it concerns how society as a whole views and manages technology itself.
Currently, the ethical and safety governance of generative AI has emerged as a shared topic in the global AI field, with governments worldwide exploring regulatory measures. Focusing on international perspectives, the EU's Artificial Intelligence Act adopts a risk-based approach, imposing varying levels of regulatory requirements on AI. This legislation has sparked strong opposition in Europe, with over 150 corporate executives signing an open letter arguing that the draft law would jeopardize Europe's competitiveness and technological sovereignty (especially in generative AI) without effectively addressing the challenges. They urged the EU to reconsider its AI regulatory plan. In contrast, the U.S. emphasizes AI innovation and development, favoring soft governance through voluntary guidelines, frameworks, or standards, such as the AI Risk Management Framework and the Blueprint for an AI Bill of Rights. In the generative AI sector, the White House has encouraged leading AI companies like OpenAI, Amazon, Anthropic, Google, Microsoft, Meta (formerly Facebook), and Inflection to make voluntary commitments to "ensuring safety, security, and trustworthy AI," calling for responsible AI development. Meanwhile, countries like Japan and South Korea prioritize a "human-centric" approach to AI governance, reflecting strong ethical considerations. Domestically, China's Interim Measures for the Management of Generative AI Services balances development and safety, promoting innovation alongside governance through inclusive, prudent, and tiered regulatory measures to enhance efficiency, precision, and agility.
In the interplay between "technology" and "regulation," major AI companies have proposed their considerations and countermeasures, implementing governance measures such as user violation monitoring, red team testing, ethical impact assessments, third-party evaluations, model vulnerability rewards, and content sourcing tools. DeepMind's policy team previously proposed a model highlighting that, beyond technical risks inherent in AI systems, risks arising from misuse must also be addressed. In September, Anthropic released its Responsible Scaling Policy (RSP), which employs technical and organizational protocols to manage risks associated with increasingly powerful AI systems. The core idea is to enforce safety standards commensurate with a model's potential risks—the more powerful the model, the more precise and rigorous the safeguards required.
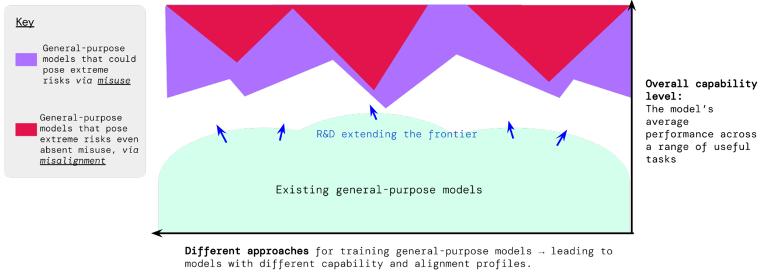

Figure 15
At the industry level, OpenAI, Anthropic, Microsoft, and Google have jointly established a new industry organization called the "Frontier Model Forum" to ensure the "safe and responsible" development and deployment of frontier AI models. Frontier AI models refer to more advanced and powerful large-scale machine learning models than current AI models, capable of performing a wide range of tasks. Specifically, the main objectives of the "Frontier Model Forum" include: promoting AI safety research, proposing best practices and standards, encouraging responsible deployment of frontier AI models, and supporting the development of positive AI applications (such as addressing climate change and cancer detection), among others.
Looking ahead, effective regulation and governance of generative AI will require the collective participation of multiple stakeholders, including governments, enterprises, industry organizations, academic groups, users and consumers, the general public, and the media. It is essential to harness the collaborative efforts of all parties to advance the concept of "responsible AI" and create secure, trustworthy generative AI applications and a responsible AI ecosystem.
In May of this year, an open letter signed by more than 350 executives, researchers, and engineers—including Geoffrey Hinton, Professor Emeritus of Computer Science at the University of Toronto; Yoshua Bengio, Professor of Computer Science at the University of Montreal; Google DeepMind CEO Demis Hassabis; OpenAI CEO Sam Altman; and Anthropic CEO Dario Amodei—sparked widespread discussion. The letter stated that the risks posed by AI to humanity are comparable to those of large-scale pandemics and nuclear war.
Of course, concerns about the existential risks (X-Risk) posed by misaligned AI (including AGI) are not entirely unfounded. More powerful AI systems are more likely to develop autonomy, making them harder to supervise and control. No one can guarantee that AI's power-seeking tendencies won't bring catastrophic consequences to humanity. It is precisely because of these concerns that the Future of Life Institute previously issued an open letter titled "Pause Giant AI Experiments: An Open Letter" to the public.
However, many scientists have voiced opposition to these views. For example, Melanie Mitchell, Professor of Computer Science at Portland State University, and Yann LeCun, head of Facebook's AI lab, argue that AI risks should not be elevated to such a level of concern. They believe limited resources should instead focus on existing threats, addressing the practical problems AI currently creates and solving specific challenges. As the debate intensifies, some suggest this is a ploy by tech companies to profit from conflict, while others argue that current discussions about AI risks are based on speculation without scientific evidence. Some contend that extinction rhetoric distracts from real issues and hinders effective AI regulation. Connor Leahy, CEO of AI company Conjecture, expressed reservations about existential risks on Twitter, emphasizing that action is more important than verbal debate.
In June of this year, the Munk Debates invited some of the aforementioned controversial parties to debate whether AI research and development pose an existential threat to humanity. Before the debate, 67% of the audience believed there was a threat, while 33% did not. After the debate, 63% still saw a threat, while 37% did not. Thus, although support for the opposing view increased slightly, the majority of the audience remained convinced that AI research and development constitute an X-Risk threat.

Figure 16
The main reasons for these differing opinions can be attributed to three factors: First, there is disagreement about the worst-case scenarios AI might bring. Second, perspectives vary along the timeline—some scholars assess AI alignment issues within a 3–5 year timeframe, while others consider a span of decades. Lastly, there is no consensus on risk tolerance, such as how much sacrifice human society is willing to make to bear the risks of AI development. However, it is important to note that discussions and debates about AI risks are not meant to promote AI 'determinism' but rather to emphasize the importance of AI safety alongside its development.
At this moment, we stand at a crossroads in AI development, where scenes from science fiction are gradually becoming reality. Every decision we make now will shape humanity's future. In this race against time, it never hurts to think more carefully. Therefore, although AI value alignment is a challenging issue, open debate and widespread discussion will guide us onto the right path. Only by pooling global resources, fostering interdisciplinary collaboration, and engaging stakeholders from politics, academia, business, and beyond in the theoretical and practical aspects of value alignment can we build consensus and ensure AI benefits humanity. We believe that, ultimately, humans will retain control.