
Multimodal Large Model KOSMOS-2.5 Excels in Processing Text-Dense Images
-
With the deep integration of vision and language, text-image understanding has become a new direction in the multimodal field. This article introduces the groundbreaking multimodal model KOSMOS-2.5, which demonstrates strong capabilities in handling text-dense images.
Paper address: https://arxiv.org/abs/2309.11419
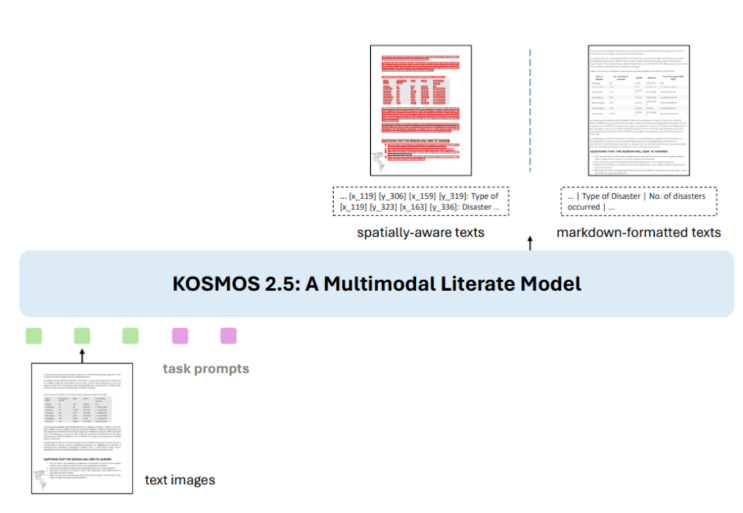
KOSMOS-2.5 is an improvement over KOSMOS-2, adopting a unified Transformer framework to achieve end-to-end understanding of text images. It consists of a visual encoder and a text decoder, connected via a resampling module, enabling simultaneous detection of text content and coordinates, as well as generating Markdown-formatted text.
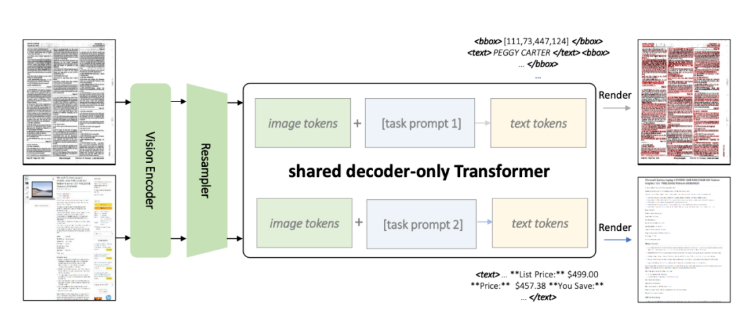
Datasets are key to KOSMOS-2.5. The article uses a massive dataset containing rich text-line images and Markdown-formatted text for pre-training, totaling 324 million entries. This multi-task joint training enhances the model's multimodal understanding capabilities.
KOSMOS-2.5 demonstrates outstanding performance in multiple text-dense image tasks: end-to-end document text recognition and Markdown generation, while also showing potential in few-shot learning. This marks KOSMOS-2.5's critical role in the broader field of text-image understanding.
Looking ahead, scaling up the model to handle more data is a key direction. The goal is to further improve the ability to interpret and generate text from images, applying KOSMOS-2.5 to more practical scenarios such as document processing and information extraction, thereby enabling language models to truly possess the capability of 'reading images and recognizing text'.