
RoBERTa: A Robustly Optimized BERT Approach
-
The BERT model holds a pivotal position in the field of Natural Language Processing (NLP). Although BERT has achieved outstanding results in multiple NLP tasks, researchers continue to refine its performance. To address these challenges, they proposed the RoBERTa model, an enhanced version of BERT with several optimizations.
RoBERTa is an improved variant of BERT that achieves superior performance across various benchmark tasks through optimization techniques such as dynamic masking, skipping next-sentence prediction, increasing batch size, and byte-level text encoding. Despite its more complex configuration, RoBERTa only introduces a small number of additional parameters while maintaining inference speeds comparable to BERT.
Key optimization techniques of the RoBERTa model:
-
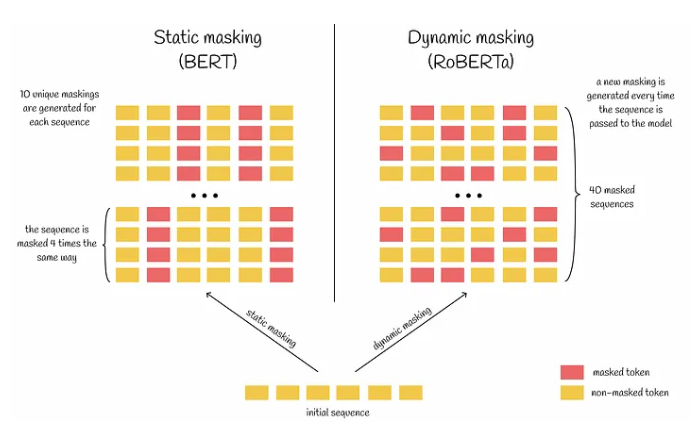
Dynamic Masking: RoBERTa employs dynamic masking, generating unique masks each time a sequence is passed to the model. This reduces data repetition during training and helps the model better handle diverse data and masking patterns.
-
Skipping Next-Sentence Prediction: The authors found that skipping the next-sentence prediction task slightly improves performance. They recommend constructing input sequences using consecutive sentences rather than sentences from multiple documents, which helps the model better learn long-range dependencies.
-
Increased Batch Size: RoBERTa uses larger batch sizes, typically improving model performance by appropriately reducing the learning rate and training steps.
-
Byte-Level Text Encoding: RoBERTa uses bytes instead of Unicode characters as the basis for subword units and expands the vocabulary size, enabling the model to better understand complex texts containing rare words.
Overall, the RoBERTa model has surpassed the BERT model in popular NLP benchmarks through these improvements. Despite its more complex configuration, it only adds 15M additional parameters while maintaining comparable inference speed to BERT. This provides a powerful tool and methodology for further advancements in the NLP field.
-