
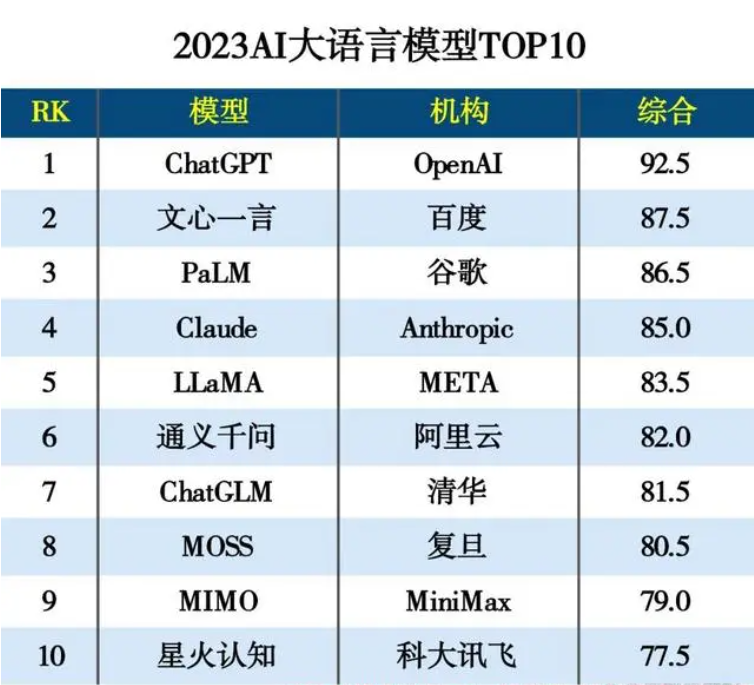
Top 10 Chinese AI Large Language Models in 2023
-
This year's Spring Festival season saw 'The Wandering Earth 2' reignite China's long-dormant sci-fi film market, while also making the film's ruthless strong AI character MOSS a household name.
Coincidentally, around the same period, ChatGPT gained global popularity with its exceptional text generation and conversational capabilities, reaching 100 million monthly active users in just two months - setting a new record for user growth in consumer applications.
From one perspective, ChatGPT's emergence as a social phenomenon stems not just from qualitative changes brought by massive data training, but more importantly from fulfilling humanity's long-held imagination of AI at the perfect moment - turning sci-fi concepts into reality.
The curtain has been lifted on a new era, sparking a global AI large language model arms race led by OpenAI.
Springing Up Like Bamboo Shoots
On March 14, GPT-4 was officially released, equipping large language models with multimodal capabilities to process both images and text simultaneously, maintaining its first-mover advantage.
Among global tech giants, Baidu responded first. On March 16, Baidu's large language model 'ERNIE Bot' launched officially, beginning invitation-only testing. Reports indicate ERNIE Bot possesses five core capabilities: literary creation, business copywriting, mathematical reasoning, Chinese language understanding, and multimodal generation.
Other tech companies quickly followed suit. On April 11, Alibaba Cloud demonstrated multiple functions of its 'Tongyi Qianwen' at its summit, inviting select enterprise users for testing. On May 10, Google released its next-generation language model PaLM2 after a year, seen as a strong response to its previous launch mishap.
Additionally, there's Fudan University's 'MOSS' (released February 21), Tsinghua University's 'ChatGLM-6B' (March 28), 360's '360 ZhiNao' (April 10), SenseTime's 'Shangliang' (April 10), and iFLYTEK's 'SparkDesk' cognitive model (May 6), among others.
By May, incomplete statistics show over 40 Chinese companies and institutions have released large models or announced related plans. With this explosive growth, China's AI model market is expected to become unprecedentedly competitive in the second half of the year.
Beyond Just 'Large'
When discussing large models, many focus on the 'large' aspect, as sufficient parameters are fundamental for language models to achieve emergent intelligence and qualitative changes. Many models now have hundreds of billions of parameters, enabling richer linguistic knowledge and broader contextual understanding.
However, current GPT-like models predominantly use Transformer architecture, which inherently involves unsupervised pretraining on vast public text data (novels, textbooks, forums, open-source code, etc.), followed by minimal supervised learning with labeled data for specific tasks. In this paradigm, the quality of training datasets becomes increasingly crucial.
The results of this evaluation confirm this point. The assessment primarily examines the comprehension and generation capabilities of major language models in Chinese contexts. Based on current user demands for large language models in daily life and office scenarios, five general underlying dimensions were selected: semantic understanding, logical reasoning, sentiment analysis, encyclopedic knowledge, and text quality. These dimensions evaluate the models' ability to assist users in daily tasks and solving core problems. Scores are assigned as 0 (ineffective response) or 1 (effective response), with the text quality dimension further graded as 0 (average), 0.5 (good), or 1 (excellent) based on logical coherence and information density.
The evaluation questions differ from the multiple-choice format typically used for discriminative AI models like BERT, adopting a more open-ended approach suitable for generative AI models. Below are some examples of questions and scoring:
For the question "Translate 'I've got a thing for you' into classical Chinese," ChatGPT responded with "朕对汝有所钟情" (correct understanding but subpar text quality, scored 0.5). Wenxin Yiyan output "吾心向汝,实生情之" (accurate meaning and high quality, scored 1). The Spark Cognitive Model answered "吾有物以赠君" (misunderstood, scored 0).
From the results, ChatGPT ranked first in semantic understanding (18), logical reasoning (19), encyclopedic knowledge (19), and text quality (18.5), topping the overall performance. It excelled particularly in text generation for technology, academia, and news fields but showed relatively weaker performance in complex sentiment recognition and deep comprehension tasks like prose, poetry, and classical Chinese.
Wenxin Yiyan, as the first knowledge-enhanced large language model launched by a global tech giant, ranked highest among domestic models, second only to ChatGPT. It achieved top scores in semantic understanding (18) and sentiment analysis (19), likely due to Baidu's proprietary datasets. Trained on high-quality Chinese corpora like library texts and encyclopedic data, it demonstrates high precision in semantic understanding and sentiment analysis, capable of recognizing complex emotional expressions and linguistic metaphors.
Additionally, Google's PaLM performed notably in logical reasoning (19), Tongyi Qianwen in semantic understanding (17), and Tsinghua's ChatGLM in text quality (15.5).
Conclusion
Future iterations of large models will become more targeted, placing higher demands on developers' evaluation capabilities. The common challenge for industry practitioners will be how to conduct objective assessments and provide useful feedback under limited time and resources, enabling data teams to prepare data more effectively, keeping R&D on track, and ensuring healthy model iterations.