
OpenAI Announces ChatGPT Safety Framework to Ensure AI Security
-
December 19 news: OpenAI, the developer of ChatGPT, has formulated plans to address the potential severe risks posed by artificial intelligence. The framework includes using AI model risk 'scorecards' to measure and track various indicators of potential harm, as well as conducting evaluations and predictions. OpenAI stated that the framework will be continuously refined and updated based on new data, feedback, and research.
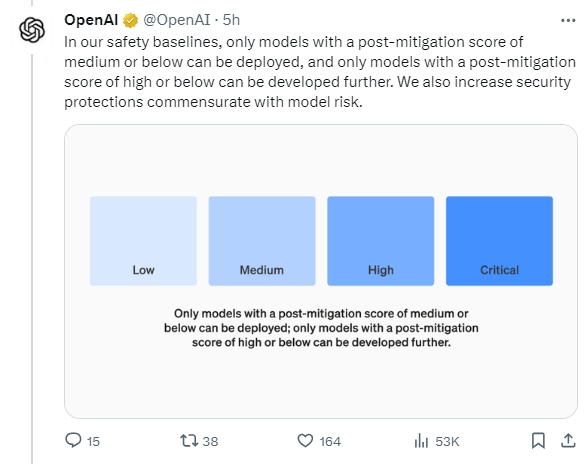
The company's 'Preparedness Framework' team will employ AI researchers, computer scientists, national security experts, and policy professionals to monitor the technology and continuously test and warn the company if they believe any AI capabilities become dangerous. The team is positioned between OpenAI's 'Safety Systems' team and the 'Superalignment' team. The former focuses on addressing issues in AI, such as injecting racial biases, while the latter researches how to ensure that AI does not harm humanity in a hypothetical future where AI surpasses human intelligence.
It is reported that OpenAI's "Preparedness" team is recruiting national security experts from outside the artificial intelligence field to help the company understand how to address major risks. They are engaging in discussions with organizations including the U.S. National Nuclear Security Administration to ensure the company can appropriately research AI risks.
The company will also allow "qualified, independent third parties" from outside OpenAI to test its technology.

OpenAI's "Preparedness Framework" stands in stark contrast to the policies of its main competitor, Anthropic.
Anthropic recently released its "Responsible Scaling Policy," which defines specific AI safety levels and corresponding protocols for developing and deploying AI models. The two frameworks differ significantly in structure and methodology. Anthropic's policy is more formal and prescriptive, directly linking safety measures to model capabilities and pausing development when safety cannot be demonstrated. OpenAI's framework is more flexible and adaptive, setting general risk thresholds for review rather than predefined levels.
Experts suggest that both frameworks have their merits and drawbacks, but Anthropic's approach may hold greater advantages in incentivizing and enforcing safety standards. Some observers also believe that OpenAI is catching up on safety protocols after the rapid and aggressive deployment of models like GPT-4. Anthropic's policy gains an edge partly because it's developed proactively rather than reactively.
Regardless of the differences, both frameworks represent significant progress in the field of AI safety. As AI models become increasingly powerful and ubiquitous, collaboration and coordination on safety technologies among leading labs and stakeholders are now crucial to ensuring beneficial and ethical AI use for humanity.