
Peking University Releases EAGLE: Tripling Large Model Inference Efficiency Without Loss
-
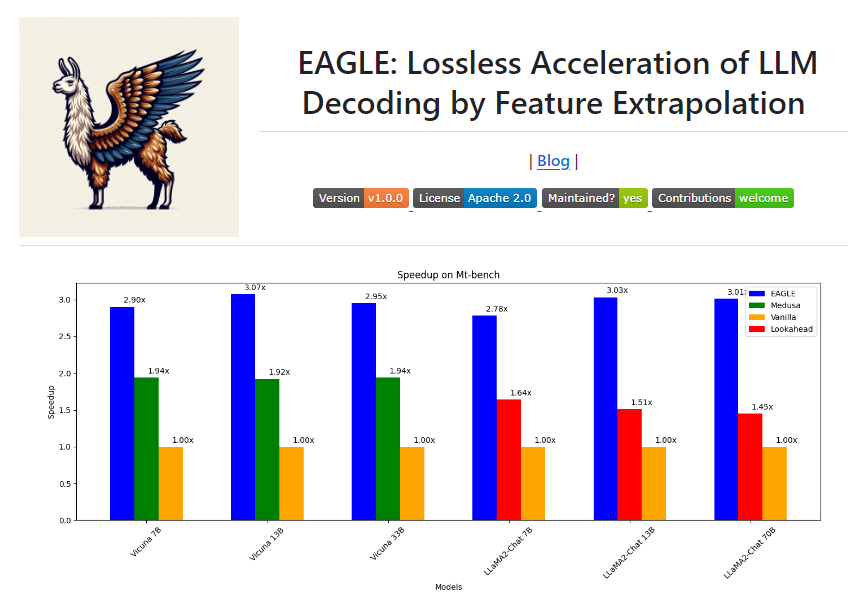
In recent years, large language models have been widely applied across various fields, but their text generation process remains costly and slow. To address this issue, the University of Waterloo, Vector Institute Canada, Peking University, and other institutions jointly released EAGLE. EAGLE aims to enhance the inference speed of large language models while ensuring the distributional consistency of output text. By extrapolating the second-top-layer feature vectors of large language models, EAGLE successfully achieves a lossless improvement in inference efficiency—3 times faster than standard autoregressive decoding, 2 times faster than Lookahead decoding, and 1.6 times faster than Medusa decoding.
Code repository: https://github.com/SafeAILab/EAGLE
To accelerate autoregressive decoding, EAGLE adopts a speculative sampling approach, combining a lightweight autoregressive head with a frozen classification head. Unlike traditional speculative sampling methods, EAGLE incorporates the token embeddings of sampled results as input, ensuring greater consistency between input and output. This innovative approach effectively handles the randomness in the sampling process, improving the accuracy of generated text.
EAGLE's working principle is based on the compressibility of feature vectors. By training a lightweight plugin, specifically an autoregressive head, it predicts the next feature from the second top layer of the original model, then uses the frozen classification head of the original LLM to predict the next word. This method of extrapolating feature vectors allows EAGLE to generate text while maintaining a distribution consistent with ordinary decoding.
Overall, the release of EAGLE marks a significant breakthrough in the inference efficiency of large language models, providing a more efficient solution for large-scale text generation tasks, and will drive the application and development of language models across various fields.