
Pika Goes Viral: Who Can Reap the Benefits of AI Video?
-
In October this year, TIME magazine released its 'Best Inventions of 2023' list. To align with the AI wave, TIME has specially introduced an 'AI category' since last year. Among the dozen applications selected this year, following established software giant Adobe and the rising star OpenAI, is the highly popular text-to-video application—Runway Gen-2.
As the technology company behind the Oscar-winning film Everything Everywhere All at Once, Runway's co-founder and CEO Cristóbal Valenzuela, when discussing his vision for AI, took a distinctly artistic approach—'AI is a new kind of camera that will forever reshape storytelling, leading us toward fully AI-generated feature films.'
However, for domestic users, the pivotal event that truly brought Runway and other AI video companies into the spotlight was the Pika project, launched by a Stanford Ph.D. dropout of Chinese descent.

Since Pika went viral, a wave of AI video evaluations has emerged in a short time, revealing clear divisions in public opinion. Some enthusiastically proclaim: "The era of AI video has arrived." Optimists believe that from text-to-image to text-to-video, video generation models are experiencing their own "GPT moment." Not long ago, Stanford's "AI Goddess" Fei-Fei Li's team collaborated with Google to launch W.A.L.T, a diffusion model for generating realistic videos.
However, others maintain a more rational perspective, acknowledging that AI video technology still has a long way to go in terms of both technical capabilities and commercialization. Pika's co-founder and CTO Chenlin Meng admitted in an interview: "I think current video generation is at a stage similar to GPT-2."
Text-to-video has always been regarded as the "holy grail" of multimodal AIGC. While the current AI video landscape boasts impressive demos, practical applications like participating in Oscar-winning film productions, and numerous industry competitors, the field still faces many challenges.
This article will primarily discuss three key questions about text-to-video generation:
1. What are the technical approaches behind text-to-video generation?
2. Why hasn't AI video reached its true 'GPT moment' yet?
3. Who currently holds a leading advantage in the industry competition?
When discussing AI video, all industry players should still thank their 'big brother'—Google.
Currently, text-to-video models in the market are built on two main technical paths: one is the Transformer-based approach widely applied in text and image generation, and the other is based on Diffusion models.
The emergence of the first approach owes much to OpenAI, in addition to the seminal paper Attention Is All You Need.
Inspired by OpenAI's Transformer architecture and large-scale pre-training on text data, several projects in the text-to-video domain—such as Google's Phenaki, ZhiPu AI, and Tsinghua University's Cog Video—have adopted this technical route. These models use Transformer-based encoding to convert text into video tokens, perform feature fusion, and ultimately generate video outputs.
Google began exploring AI-generated videos early with Phenaki, prompting online discussions like When will AI win an Oscar?

However, text-to-video models based on the Transformer architecture have significant drawbacks. As seen from OpenAI's previous "brute force aesthetics," they pose substantial challenges in terms of training costs and the need for paired datasets. For instance, researchers working on Phenaki not only used text and images for training but also incorporated 1.4-second, 8FPS short video clips with text.
With the rapid growth of diffusion models in the image generation field, researchers have gradually extended these models to video generation. Notably, companies that thrived in the diffusion model wave, such as Stability.ai (creator of the classic text-to-image model Stable Diffusion) and its close partner Runway, have not missed the next wave of video generation.
On this technological path, both tech giants and startups have flourished. Major players like Meta's Make-A-Video and Emu Video, NVIDIA's Video LDM, and Microsoft's NUWA-XL, as well as startups like Stable AI and Runway, all follow this logic.
Two technologies alternate, with diffusion models currently dominating, but there is no superiority or inferiority. However, behind the technological iteration, we can observe three major trends.
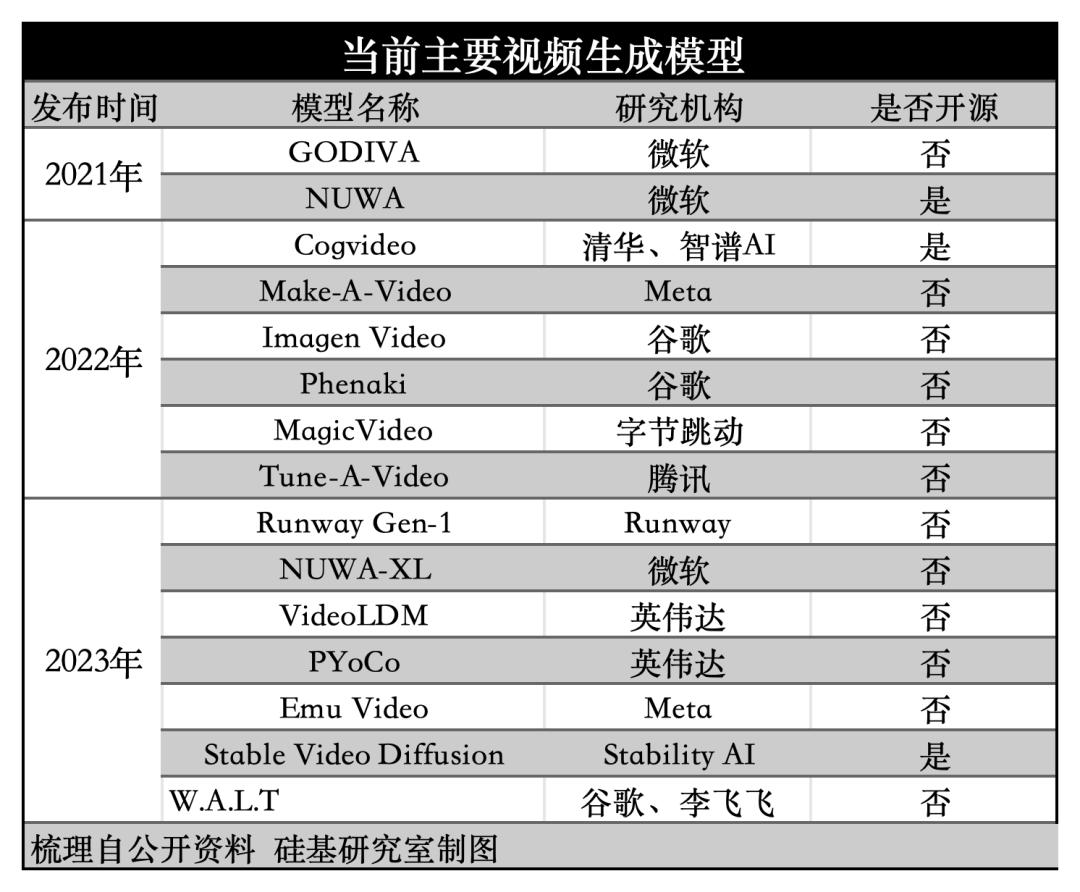
First, in terms of the number of participants, large tech companies dominate, and there is no phenomenon of 'a hundred schools of thought contending' as seen in text-to-image models. The reason behind this is that the difficulty level follows the order: text > image > video, making text-to-video a high barrier to entry.
Second, from the data perspective, the scale of AI video training datasets is becoming larger and more diverse. Taking Runway Gen-2 as an example, its training data includes 240 million images, 6.4 million video clips, and hundreds of millions of learning examples.
Thirdly, most model vendors have chosen to pursue closed-source approaches in text-to-video generation. The underlying reason is that text-to-video places high demands on computational power and model engineering capabilities. Professor Dong Xu from the University of Hong Kong and CEO of Xutu Intelligence mentioned in a recent interview: "Text-to-video isn't something just anyone can do. The open-source community might not be viable either because the computational requirements are too high. While the open-source community can handle text-to-image generation, text-to-video is likely impractical."
Chenlin Meng, co-founder and CTO of Pika, candidly stated in a recent interview: "I think current video generation is at a moment similar to GPT-2."
In other words, behind the flashy demos, there's still some distance to go before AI video truly integrates into video production workflows and meets the broader video needs of the general public.
First, from the current output effects of text-to-video models, limitations such as short duration, low resolution, and illogical content generation still constrain their frequency of use.

At the core, this still boils down to the complexity of video scenarios.
On the data front, compared to collecting high-quality data for text-to-image generation, text-to-video models require vast amounts of data to learn captions, frame photorealism, and temporal dynamics. Additionally, since video lengths vary, segmenting videos into fixed-frame clips during training disrupts the alignment between text and time, affecting model performance.
In video scenarios, beyond spatial location information, temporal information must also be considered. Therefore, achieving high-quality video generation demands exceptional computational and reasoning capabilities. Current text-to-video models still struggle with understanding object motion coherence and adapting to everyday versus non-everyday scene transitions, indicating significant room for improvement.
Secondly, from a business model perspective, current text-to-video applications follow a pricing model similar to image generation, with commercialized applications like Runway Gen-2 primarily charging based on generation volume. Compared to the early commercialization stages of text-to-image applications, platforms like Runway still have a long way to go.
Finally, industry players' knowhow in complex video production workflows still needs improvement. The video production process is generally divided into pre-production and post-production. Pre-production includes scriptwriting, storyboard design, and material shooting and organization, while post-production involves rough cuts, music, special effects, color grading, and subtitles. AI plays different roles in each stage, and model developers can help creators improve quality and efficiency by establishing relevant toolchains.
However, the competitive thresholds vary across different stages. Lower-threshold tasks include subtitle addition, while higher-threshold tasks involve video editing functions like fine-tuning shots. Different video creators have different workflows, making it difficult for any single solution to dominate the entire process.

This is why currently, the mature or popular AI video works in the market are not created by a single model or application alone, but rather through the combination of multiple models and tools (such as ChatGPT + Midjourney + Runway).
From text-to-image to text-to-video, the upgrade in multimodal capabilities has brought a new wave of AI video advancements. However, as mentioned earlier, AI video has not yet reached its "GPT moment," so the competition is still in its early stages.
Looking at the iteration path of text-to-image models, although many unicorn companies like Midjourney have quickly commercialized and achieved revenue by accumulating user scale in the early stages, thereby building certain barriers.
Therefore, the competition in the video field will likely resemble the competitive landscape of large language models. As the co-founder of Pika mentioned: "I believe that in the future, one company will lead the video field by one or two years, charging ahead while others follow."
In such an uncertain early-stage market, the players who stand out are invariably those demonstrating strong PMF (Product-Market Fit).
Among them, whether it's HeyGen, which focuses on AI lip-syncing and translation for short videos, or the now-viral Pika with its editable and cinematic-quality effects, the essence lies in quickly identifying a market that aligns with their product.
HeyGen's CEO and co-founder Xu Zhuo, who achieved $1 million in Annual Recurring Revenue (ARR) in just seven months, recently shared in an article: "Without PMF, technology is irrelevant."
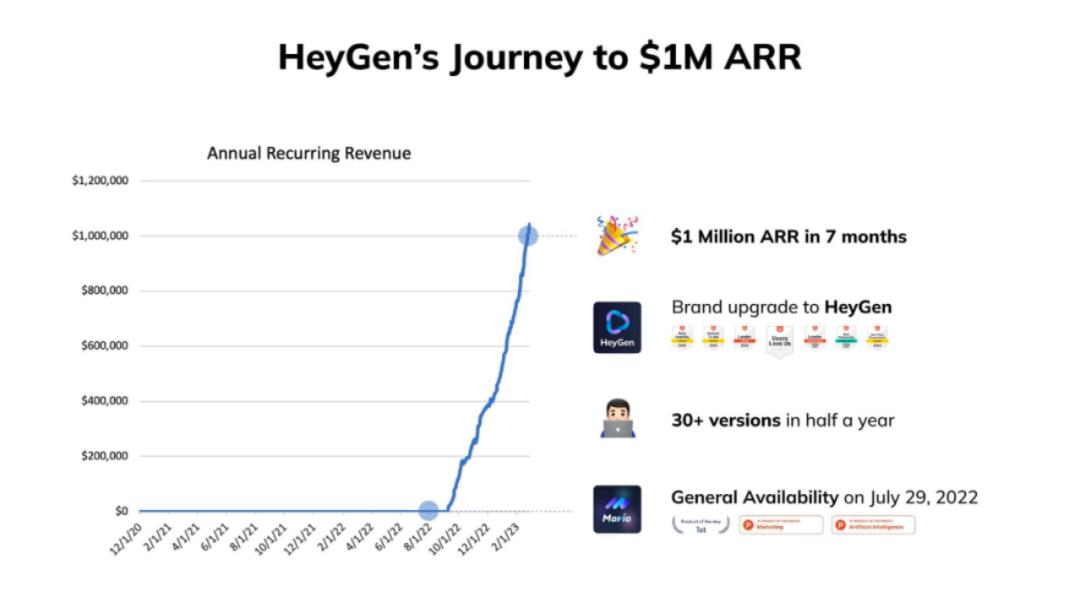
HeyGen achieved $1 million in annual recurring revenue (ARR) within 7 months.
To some extent, this reflects a trend: Compared to the competition in text-to-image generation, startups in the higher-barrier AI video field demonstrate a stronger willingness to commercialize.
The reasons behind this anxiety are not hard to understand.
One major constraint is computing power, as the video domain demands significantly higher computational resources. A co-founder of Pika once gave an example: "For Stable Diffusion, someone might train a decent model from scratch using just 8 A100 GPUs. But for video models, 8 A100s may not be enough—it might not even yield a usable model."
She even admitted that the open-source community may not have sufficient computational power to train new video models. Apart from some open-source models released by large companies, it's challenging for ordinary open-source communities to conduct exploratory work.
Second is the fierce competitive environment. In the AI video product space, on one hand, as mentioned above, leading tech giants have already entered the field, though their products haven't been fully publicly tested yet. On the other hand, there are established software giants like Adobe targeting professional users, and companies like Runway that have first-mover advantage.
There's also a category of lightweight video production products like HeyGen, Descript, and CapCut.
Large tech companies have computational advantages, especially since no major player has clearly adopted an open-source approach (only Stability AI has released an open-source generative video model, Stable Video Diffusion). Companies like Adobe have the advantage of integrating AI video features with their existing businesses, creating more frequent usage scenarios. Adobe previously acquired an AI video startup, Rephrase.ai.
Lightweight video production products are inherently targeted at non-professional users, which means the key lies in quickly capturing this audience through differentiated advantages and establishing mindshare.
As the old saying goes, people always overestimate technology in the short term and underestimate it in the long term - and AI video is no exception.