
Kai-Fu Lee's Yi-34B Achieves New Record, Surpassing Mainstream Large Models Like LLaMA2 with 94.08% Win Rate!
-
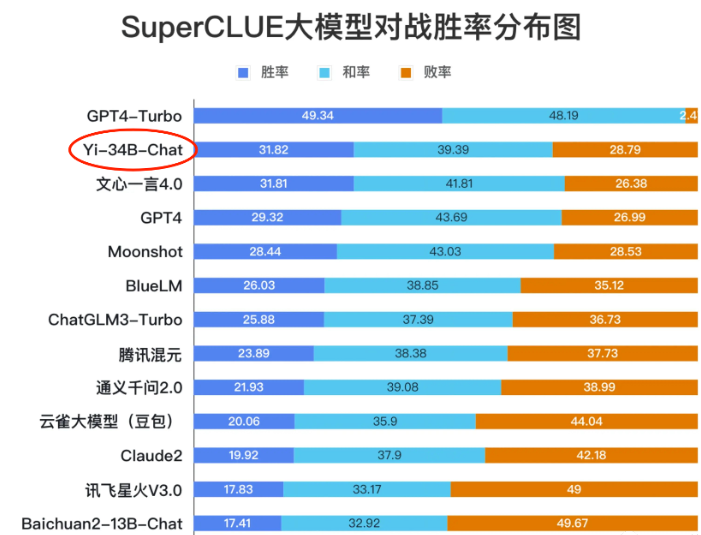
December 11 News: Recently, Kai-Fu Lee's Yi-34B-Chat model has performed exceptionally well in multiple evaluations. With a 94.08% win rate, it has surpassed mainstream large models like LLaMA2 and ChatGPT. Notably, in the LMSYS ORG rankings led by UC Berkeley, it achieved an Elo score of 1102, matching GPT-3.5. Additionally, on the Chinese SuperCLUE leaderboard, Yi-34B-Chat secured a 31.82% win rate, ranking just behind GPT4-Turbo.
Through real-world dialogue scenario tests, Yi-34B-Chat has demonstrated superior capabilities. Whether discussing the development direction of Transformer model architectures or generating Xiaohongshu (Little Red Book) copywriting, Yi-34B-Chat's responses are well-reasoned and align with mainstream styles. In terms of Chinese comprehension, Yi-34B-Chat also exhibits outstanding accuracy in handling complex Chinese understanding tasks.
Project Address: https://huggingface.co/01-ai
The remarkable performance of the Yi-34B-Chat model stems not only from its robust foundational series but also benefits from the innovative alignment strategies developed by the AI alignment team. By adopting a lightweight instruction fine-tuning approach, a two-phase innovative training method that enhances individual capabilities and integrates multiple abilities, and unique designs focusing on data quality and instruction diversity, the Yi-34B-Chat model excels in various aspects.
In its first month of open-source release, the Yi-34B model achieved impressive results, with 168,000 downloads on the Hugging Face community and 12,000 downloads on the ModelScope community, along with over 4,900 Stars on GitHub. Several renowned companies and institutions have developed fine-tuned models based on the Yi foundation, such as OrionStar-Yi-34B-Chat by OrionStar and SUS-Chat-34B by IDEA Research Institute, both demonstrating excellent performance. In experiments on GPU-accelerated large models, Yi-6B became a benchmark project.
Developer Eric Hartford raised concerns that the Yi model uses the same architecture as the LLaMA model, sparking accusations of "plagiarism." The 01.AI team promptly addressed the issue by resubmitting the model and code on various open-source platforms, completing version updates. However, this minor issue was misinterpreted domestically, leading to a media storm. The team emphasized that they built the Yi series models from scratch and that the renaming was solely for comparative experimental purposes.
This series of achievements and challenges collectively outlines the successful trajectory of the Yi-34B-Chat model. Despite some controversies, its performance in technological innovation and user experience continues to attract significant attention.