
Tencent AI Lab Collaborates with University of Sydney to Introduce GPT4Video, Enhancing LLM's Video Generation Capabilities
-
Recent significant progress has been made in the field of multimodal large language models (MLLMs), but there remains a noticeable gap in multimodal content generation. To address this gap, Tencent AI Lab and the University of Sydney have jointly introduced GPT4Video, a unified multi-model framework that endows large language models with unique capabilities for video understanding and generation.
The main contributions of GPT4Video can be summarized as follows: the introduction of GPT4Video, a versatile framework that enhances LLMs' capabilities for both video understanding and generation; the proposal of a simple yet effective fine-tuning method aimed at improving the safety of video generation, offering an attractive alternative to commonly used RLHF methods; and the release of a dataset to facilitate future research in the field of multimodal LLMs.
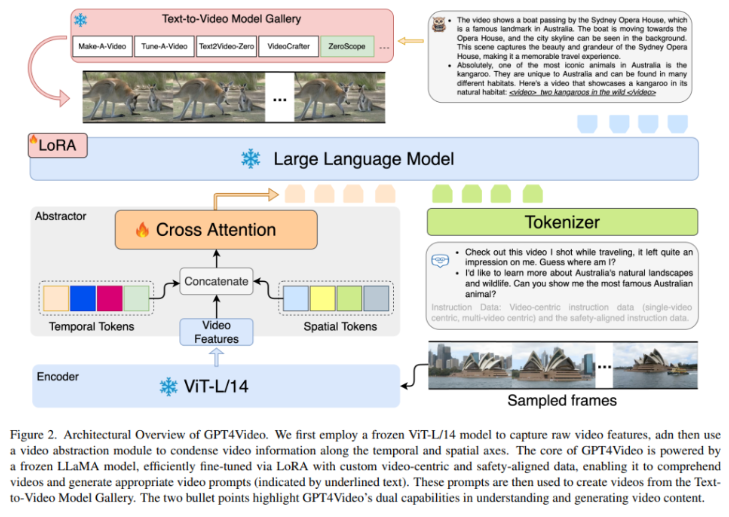
GPT4Video addresses the limitations of existing multimodal large language models (MLLMs), which, while proficient in handling multimodal inputs, fall short in generating multimodal outputs. The architecture of GPT4Video includes three key components: a video understanding module, which utilizes video feature extractors and video summarizers to encode and align video information within the LLM's word embedding space.
The basic structure of LLMs includes word embeddings, multi-head self-attention mechanisms, and feed-forward neural networks for processing textual information. The video generation module utilizes video feature extractors and decoders to produce videos from the LLM's word embedding space. A safety fine-tuning method is implemented by incorporating safety objectives and generator control strategies to enhance the security of video generation.
GPT4Video fills a gap in the field of multimodal content generation and provides a unified multi-model framework, enabling large language models to understand and generate videos. The research also proposes a simple yet effective fine-tuning method and releases a dataset, facilitating future studies on multimodal LLMs.