
Strengthening Software Layout: Full Disclosure of AMD's Most Powerful AI Chip
-
At a grand launch event in San Francisco this June, AMD CEO Lisa Su introduced the MI300A and also unveiled the company's new-generation AI chip, the MI300X, boasting 153 billion transistors. With its powerful bandwidth and memory, coupled with the near-monopoly of the AI market by NVIDIA, AMD's chip has garnered widespread attention from AI professionals since its release.
At the company's Q3 earnings conference at the end of October, Lisa Su optimistically predicted that revenue from data center GPUs would reach approximately $400 million in Q4 this year. With continued growth, this figure could exceed $2 billion by 2024. "This growth will make the MI300 the fastest product in AMD's history to surpass $1 billion in sales," Lisa Su stated.

Based on these outstanding performances, Lisa Su revised her forecast for data center AI accelerators during today's 'Advancing AI' conference speech. A year ago, she estimated the AI accelerator market at $30 billion in 2023, projecting it to reach $150 billion by 2027, implying a CAGR of about 50%. However, Lisa Su now believes the AI accelerator market will hit $45 billion in 2023, with a CAGR of up to 70% in the coming years, driving the total market to $400 billion by 2027.

AMD has simultaneously unveiled the MI 300X and MI 300A, while also providing more details about RCom 6.
As shown in the image, the AMD Instinct MI300X adopts an 8 XCD, 4 IO die, 8 HBM3 stacks, up to 256MB AMD Infinity Cache, and a 3.5D packaging design. It supports new mathematical formats such as FP8 and sparsity, making it a solution entirely focused on AI and HPC workloads.
From what we understand, XCD refers to AMD's compute Chiplet in GPUs. As illustrated, the MI 300X's 8 XCDs contain 304 CDNA 3 compute units, which means each compute unit includes 34 CUs (CU: Computing Unit). In comparison, the AMD MI 250X has 220 CUs, marking a significant leap forward.

In terms of I/O, AMD has once again employed Infinity Cache technology in this generation of accelerators, which they refer to as a "massive bandwidth amplifier." Data shows that this is a technology AMD introduced with RDNA 2. At the time of its launch, AMD stated that they aimed to use Infinity Cache technology to enable GPUs to not only have fast-access, high-bandwidth on-chip cache but also achieve low power consumption and low latency simultaneously. In the MI 300X, this cache has been increased to 256MB. Additionally, AMD has equipped this chip with 7×16-lane fourth-generation AMD Infinity Fabric links to support its I/O performance.

Specifically regarding packaging, AMD has introduced what they call "3.5D packaging" technology by incorporating 3D hybrid bonding and 2.5D silicon interposers.
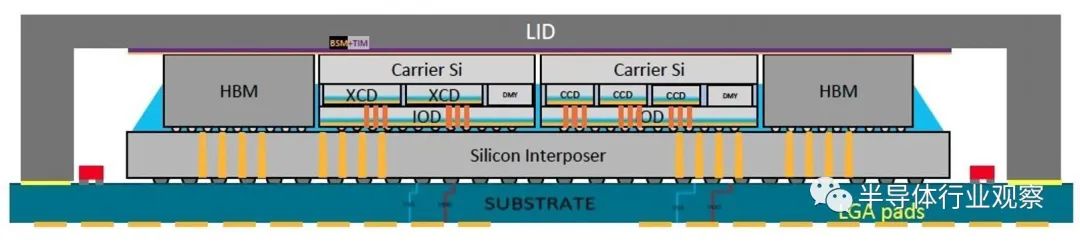
According to IEEE, this integration was accomplished using TSMC's SoIC and CoWoS technologies. The latter employs so-called hybrid bonding to stack smaller chips on top of larger ones, a technique that directly connects the copper pads on each chip without soldering. This method is used in the production of AMD's V-Cache, an extended cache memory chip stacked on its highest-end CPU chiplets. The former, known as CoWoS, stacks chiplets on a larger silicon interposer designed to accommodate high-density interconnects.
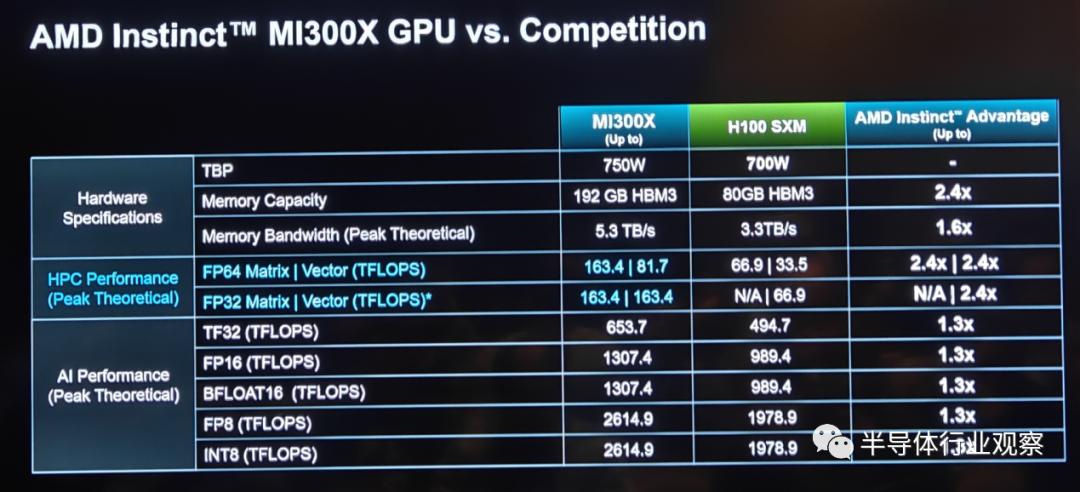
In terms of HBM3 configuration, the MI300X features eight physical stacks of HBM, delivering a total capacity of 192GB—2.4 times that of NVIDIA's H100 with 80GB HBM3, consistent with previous data. However, regarding bandwidth, AMD's latest presentation indicates a peak memory bandwidth of 5.3TB/s for the MI300X, differing from the previously stated 5.2TB/s. This represents a 2.4-fold increase over the NVIDIA H100 SXM's 3.3TB/s memory bandwidth.
As shown in the figure above, benefiting from these leading designs, the MI300X outperforms competitors in multiple performance tests. According to AMD, their Instinct product strategy is built on four strategic pillars: easy migration, performance leadership, commitment to openness, and customer focus. Easy migration means the MI300X will be compatible with existing hardware and software frameworks; performance leadership signifies uncompromising leading performance; commitment to openness emphasizes the company's investment and active participation in open-source standard systems across the ecosystem; and customer focus reflects the company's dedication to creating roadmaps tailored to customer needs.

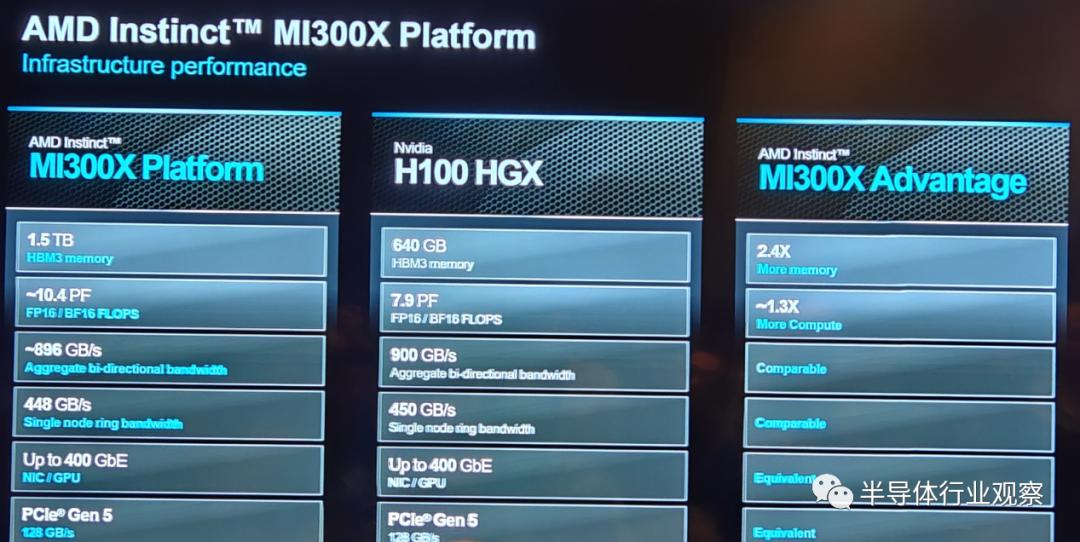
In fact, as illustrated, AMD has utilized eight MI300X units to build a high-performance platform, with specific parameters shown in the figure below, making it an industry-leading standard design. More importantly, due to the product's compatibility, it significantly reduces the time and cost for customers to migrate hardware or software.

AMD summarizes that the next-generation Instinct platform, built on industry-standard OCP design, is equipped with eight MI300X accelerators, delivering an industry-leading 1.5TB HBM3 memory capacity. The industry-standard design of the AMD Instinct platform allows OEM partners to integrate MI300X accelerators into existing AI products, simplifying deployment and accelerating the adoption of AMD Instinct accelerator-based servers.
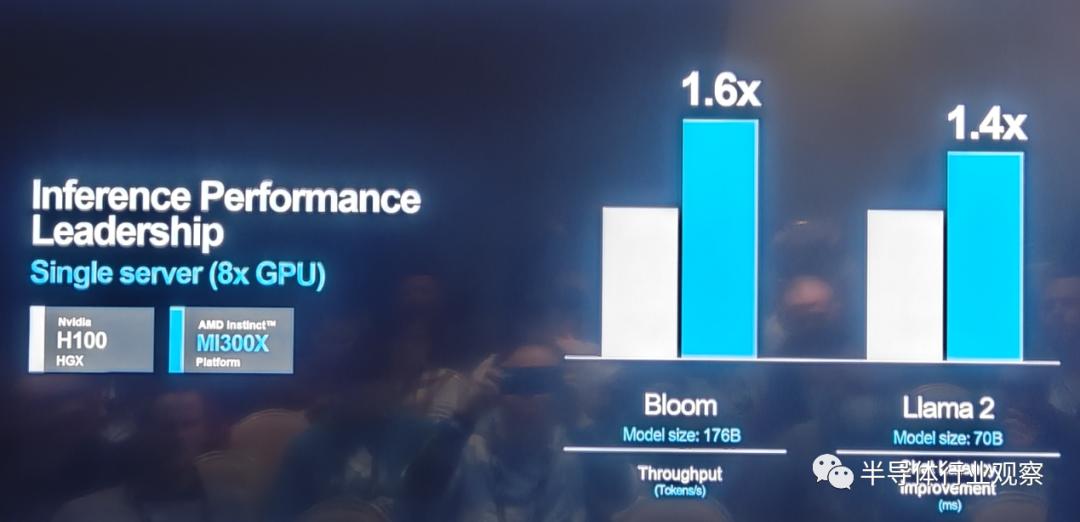
Compared to the Nvidia H100 HGX, the AMD Instinct platform can achieve up to 1.6 times higher throughput when running inference on LLMs like BLOOM 176b, and it is the only option on the market capable of running inference on 70-billion-parameter models like Llama2.
In key AI kernel performance metrics, the MI 300X-based platform outperforms its competitors.
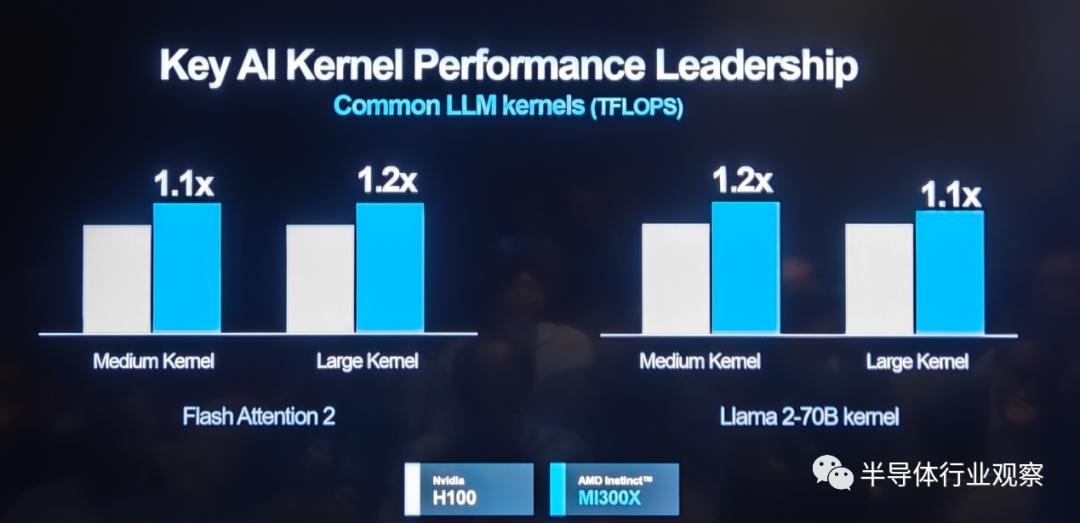
For certain model training tasks, as shown below, the AMD MI 300X remains competitive when compared to NVIDIA's H100.
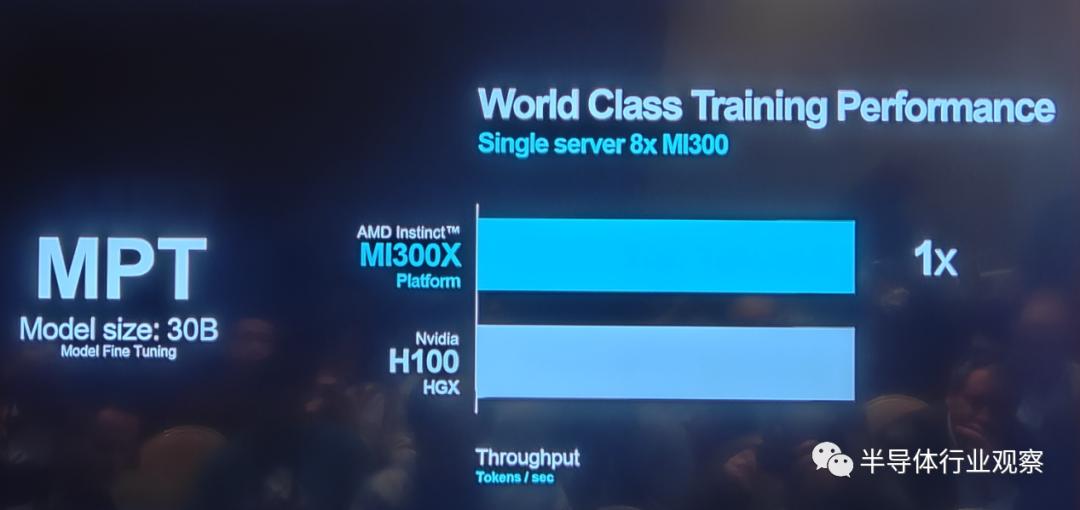
The data in the following chart reveals additional advantages of AMD's latest chip platform in both training and inference applications.

At this launch event, AMD provided in-depth details about the industry's first APU accelerator - the MI300A.
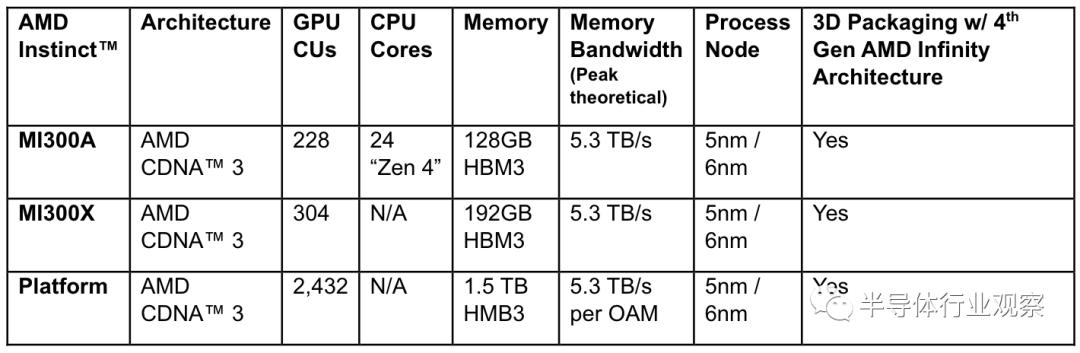
As the world's first data center APU designed for HPC and AI applications, the AMD Instinct MI300A APU leverages 3D packaging and 4th-gen AMD Infinity Architecture to deliver leading performance on critical HPC and AI convergence workloads. The MI300A APU combines high-performance AMD CDNA 3 GPU cores, the latest AMD "Zen 4" x86 CPU cores, and 128GB of next-generation HBM3 memory. Compared to the previous-generation AMD Instinct MI250X, it achieves approximately 1.9x better performance per watt on FP32 HPC and AI workloads.

In terms of product design, as shown in the figure above, the MI 300A and MI 300X share many similarities, such as 3.5D packaging, 256MB of AMD Infinity Cache, and 4 IODs. However, there are differences in HBM and computing units. For example, while the MI 300A also adopts HBM 3 design, its capacity is smaller than that of the MI 300X.
In terms of I/O die, although it has the same Infinity Cache as the MI 300X, the MI 300A is configured with 4×16 fourth-generation Infinity Fabric Links and 4×16 PCIe 5, which differs from the MI 300X.
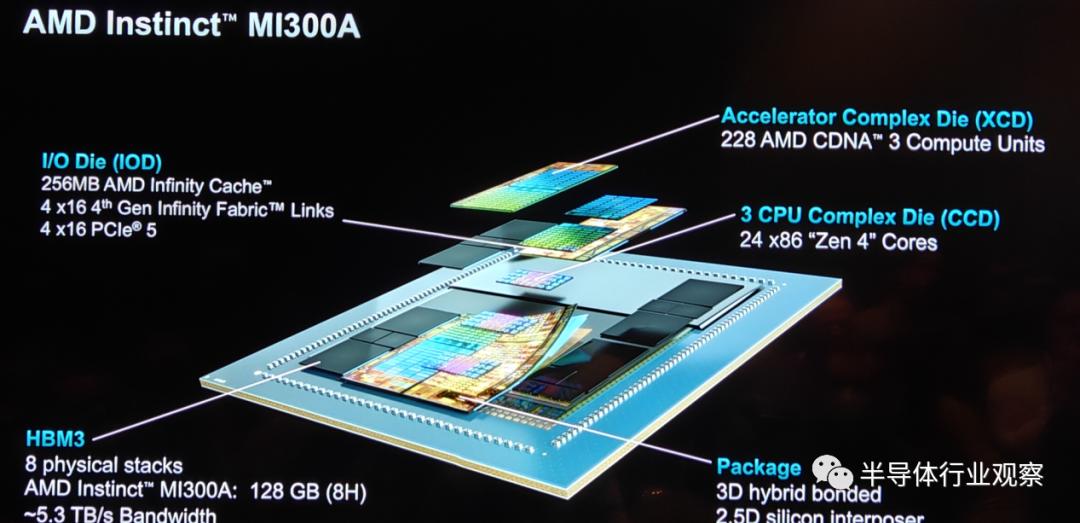
The difference in computing units between these two MI 300 series products is particularly notable. Unlike the MI 300X, which only uses XCD computing units, the MI 300A incorporates 6 XCDs and 3 CCDs, meaning it has 228 CDNA 3 CUs and 24 "Zen 4" cores.
In fact, the "CPU+GPU" design is not exclusive to AMD. For example, Nvidia's GH200 also adopts the same concept, and Intel once planned an XPU design for Falcon Shores. Although Intel canceled the XPU design, AMD continues to pursue this path. According to their previous statements, transitioning from a consistent memory architecture to a unified memory APU architecture is expected to improve efficiency, eliminate redundant memory copies, and avoid copying data from one pool to another, thereby reducing power consumption and latency.
However, as reported by IEEE, Nvidia and AMD have different approaches. On Nvidia's side, both Grace and Hopper are independent chips, integrating all necessary functional blocks for a system-on-chip (computing, I/O, and cache). They are horizontally connected via Nvidia's NVLink Chip-2-Chip interconnect and are quite large—almost reaching the size limits of lithography technology.
AMD, on the other hand, integrates three CPU chips and six XCD accelerators using AMD Infinity Fabric interconnect technology. With this functional decomposition, all silicon components in the MI300 become much smaller. The largest I/O die is even less than half the size of Hopper, and the CCD is about one-fifth the size of the I/O die. This compact size offers advantages in yield and cost.
AMD summarized in today's presentation that this APU design offers advantages such as unified memory, shared AMD Infinity Cache, dynamic power sharing, and ease of programming, which will unlock unprecedented new performance experiences.
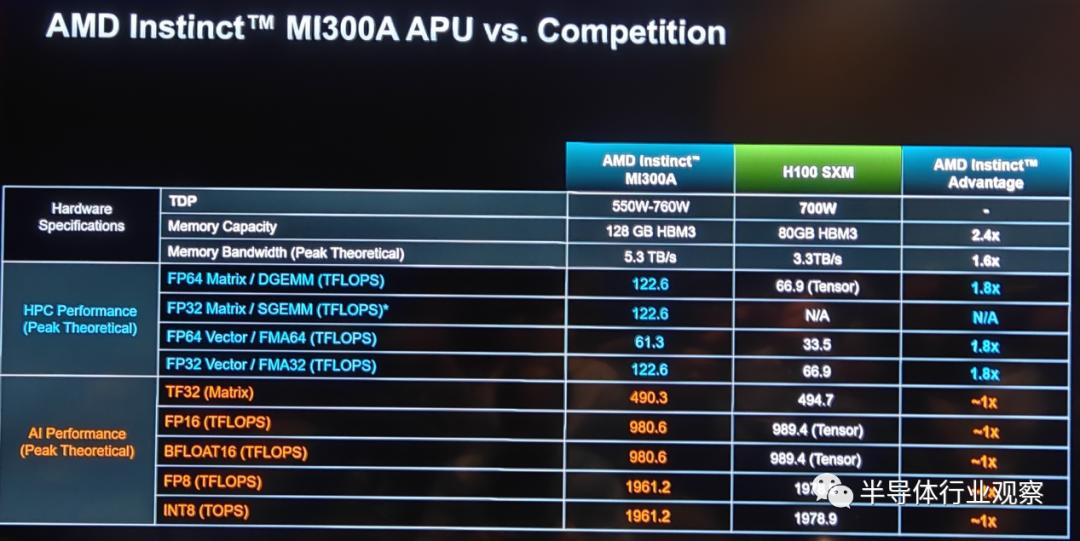
In actual comparisons with Nvidia's H100, the MI 300A holds its own. For example, in the HPC OpenFOAM motorbike test, the AMD MI 300A outperforms its competitor by four times.
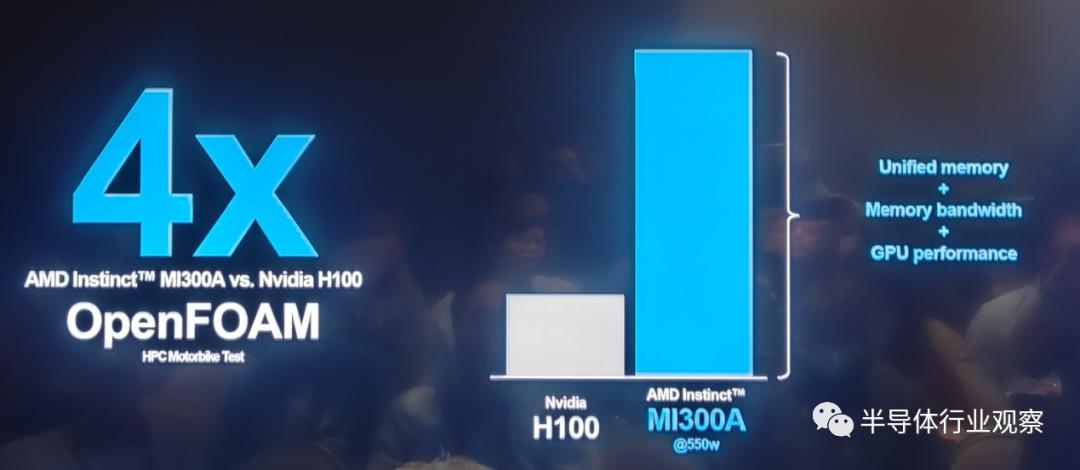
In terms of performance per watt at Peak HPC, the MI 300A achieves twice that of Nvidia's GH200, which also features a "CPU+GPU" packaging design.

In multiple HPC performance tests, the MI 300A performs on par with the H100.
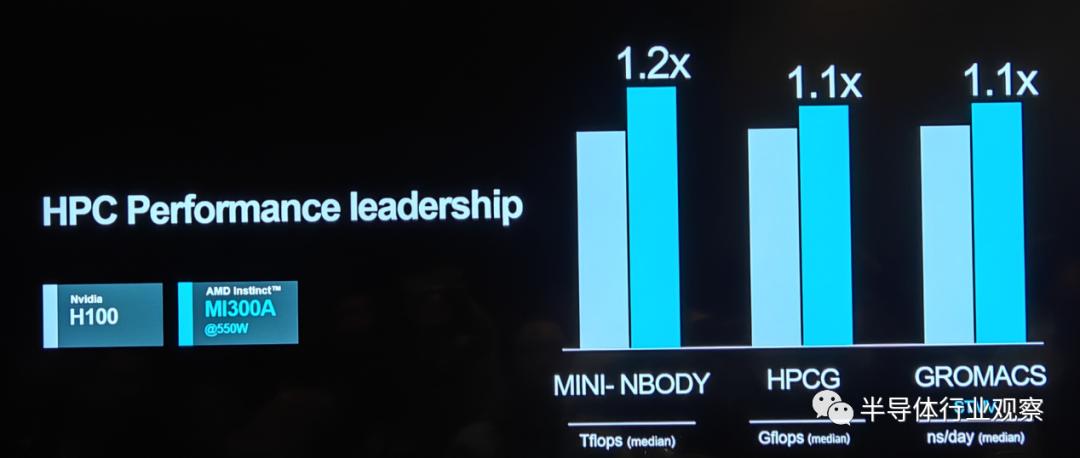
Thanks to its outstanding performance, AMD's MI 300 series has gained significant recognition from customers, which explains the rapid growth in orders for AI accelerators as disclosed by Lisa Su. The MI 300A is particularly suited for data center and HPC applications, with notable deployments such as the El Capitan supercomputer, expected to be the world's fastest. Meanwhile, the MI 300X is optimized for generative AI use cases. AMD emphasized during the launch that both products have received high praise from clients.
Undeniably, AMD has made significant progress in hardware over the years and achieved commendable performance. However, as Semianalyst Dylan Patel pointed out, for AI accelerators, all the devilish details lie in the software.
"Over the past decade, the landscape of machine learning software development has undergone significant changes. Many frameworks have emerged and faded, but most heavily rely on leveraging Nvidia's CUDA and perform best on Nvidia GPUs," emphasized Dylan Patel. He also noted that AMD's ROCm has not performed as well in the past, with its RCCL libraries (Communications Collectives Libraries) generally falling short.
To address this, AMD is bolstering its software capabilities, with ROCm 6 being a highlight of recent announcements.
AMD President Victor Peng has repeatedly emphasized the importance of software, even stating that software is AMD's top priority for making a market impact.
At the June conference, Victor Peng introduced that AMD possesses a comprehensive library and toolset called ROCm, which can be utilized for its optimized AI software stack. Unlike the proprietary CUDA, this is an open platform. Over time, the company has continuously refined the ROCm suite. AMD is also collaborating with numerous partners to further enhance its software, facilitating AI development and applications for developers.
Over the past six months, AMD has indeed achieved significant progress.

It is reported that AMD has launched the latest version of its AMD Instinct GPU open-source software stack, ROCm 6, which is optimized for generative AI, particularly large language models. It also supports new data types, advanced graphics and kernel optimizations, optimized libraries, and state-of-the-art attention algorithms.

When comparing ROCm 6 with MI300X to ROCm 5 with MI250, the overall latency performance for text generation on Llama 2 with 7 billion parameters improved by approximately 8 times.
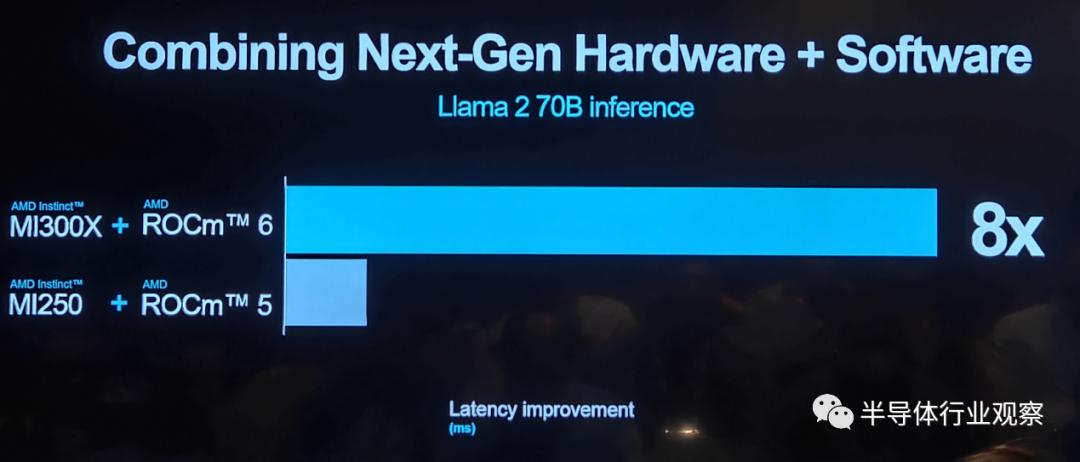
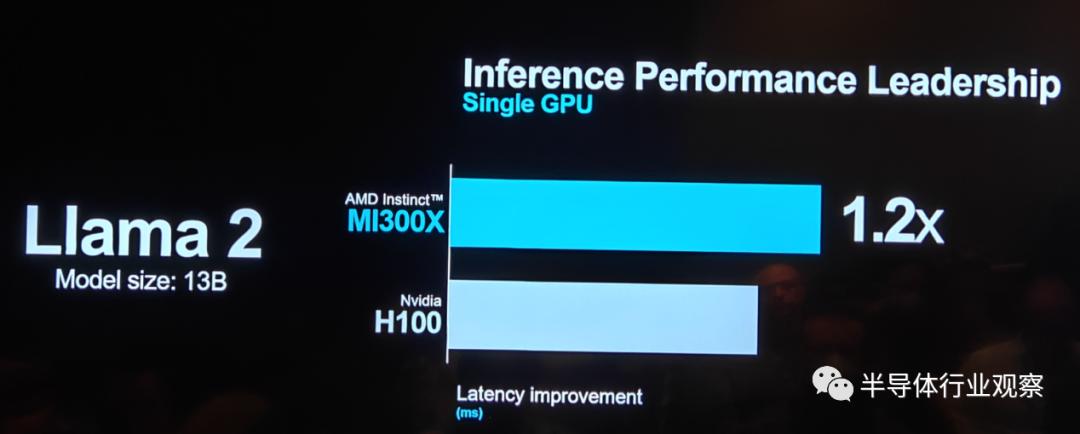
During inference performance testing on Llama 2 with 13 billion parameters, the latency performance of MI300X slightly outperformed NVIDIA's H100.
With the support of these hardware and software advancements, three AI startups—Databricks, Essential AI, and Lamini—along with AMD, discussed how they leverage AMD Instinct MI300X accelerators and the open ROCm 6 software stack to deliver differentiated AI solutions for enterprise customers. The hottest AI company, OpenAI, also announced support for AMD Instinct accelerators in Triton 3.0, providing out-of-the-box compatibility and enabling developers to work at a higher level on AMD hardware.
Meanwhile, Microsoft, Meta, and Oracle shared their collaborations with AMD. Microsoft explained how deploying MI300X empowers Azure ND MI300X v5 VMs and optimizes AI workloads. Meta is deploying MI300X and ROCm 6 in data centers for AI inference tasks, with AMD showcasing optimizations for Llama2 on ROCm 6. Oracle announced plans to offer bare-metal computing solutions based on MI300X accelerators and will soon provide generative AI services powered by MI300X.
Additionally, several data center infrastructure providers, including Dell, HP, Lenovo, Supermicro, Gigabyte, Inventec, QCT, Ingensys, and Wistron, have already integrated or plan to integrate MI300X into their products.
Like the data center CPU market in the past, the GPU market is currently dominated by a single player—an open secret. However, whether from the perspective of market development, customer demand, or future needs, having alternative AI accelerator suppliers is an urgent necessity.
With the MI 300 series, AMD is undoubtedly one of the top contenders. Let's look forward to Lisa Su leading this team, which has created miracles in the CPU field over the past few years, to achieve another glory in the GPU market.