
The AI Text-to-Video Track Will Bring New Growth and Prosperity to Various Industries
-
In the current AI landscape, applications for text and image generation are already abundant, with related technologies constantly evolving.
In contrast, AI text-to-video remains a largely unconquered frontier.
Issues like flickering, flashing, and short duration have kept AI-generated videos at a "just for fun" level, making them difficult to use, let alone provide commercial value.
Until recently, a viral application reignited interest in this field.
You've likely heard a lot these days about this text-to-video AI called Pika.
Therefore, we will not elaborate on Pika's various functions and features here, but directly address one question:
Does the emergence of Pika indicate how far AI text-to-video is from the ideal effect people expect?
To be realistic, the current AI text-to-video field is both highly challenging and valuable.
The biggest challenge among them is undoubtedly the jittering issue that makes the footage appear 'twitchy'.
Anyone who has used text-to-video AI tools like Gen-2 Runway can deeply relate to this issue.
Jitter, flickering, and occasional abrupt scene changes make it difficult to achieve stable generation results.
Behind these "glitchy" phenomena lies the fundamental problem of weak connections between frames.
Specifically, current AI video generation technology closely resembles early hand-drawn animation techniques. Both methods involve creating multiple still frames first, then linking them together to simulate motion through gradual transitions between frames.
Whether it's hand-drawn animation or AI-generated videos, the first step is always to determine the key frames. Key frames define the position and state of characters or objects at specific moments.
To make the animation appear smoother, transition frames (also known as "in-between frames" or "interpolated frames") need to be added between these key frames.
The problem arises when generating these transition frames. While the dozens of images generated by AI may look stylistically similar, the details can vary significantly when strung together, often resulting in flickering in the video.

This flaw has become one of the biggest bottlenecks in AI-generated video production.
The root cause behind this is still the so-called "generalization" problem.
In simple terms, AI's learning of videos relies heavily on vast amounts of training data. If the training data doesn't include certain specific transition effects or movements, the AI finds it difficult to learn how to apply these effects when generating videos.
This issue becomes particularly evident when dealing with complex scenes and actions.
Beyond the keyframe problem, AI video generation faces numerous challenges, and these difficulties are on an entirely different level compared to static tasks like AI image generation.
For example:
Motion Coherence: To make videos appear natural, AI needs to understand the inherent patterns of motion and predict the movement trajectories of objects and characters over time.
Long-term and Short-term Dependencies: In video generation, some changes may occur over longer time frames (such as a character's prolonged actions), while others may happen in shorter time frames (such as an object's instantaneous movement).
To address these challenges, researchers have adopted various methods, such as using Recurrent Neural Networks (RNN), Long Short-Term Memory networks (LSTM), and Gated Recurrent Units (GRU) to capture temporal dependencies.
However, the key point is that current AI text-to-video generation hasn't established a unified and clear technical paradigm like LLMs (Large Language Models). The industry is still in the exploratory phase regarding how to generate stable videos.
The AI text-to-video field is both highly challenging and immensely valuable.
Its value lies in its ability to genuinely address pain points and needs across many industries, unlike many current "shell" applications that merely add minor enhancements or operate in isolation.
This can be examined from two dimensions: "time" and "space," to assess the future potential of AI text-to-video.
From a temporal perspective, one of the most critical criteria for determining whether a technology is a "false trend" or a fleeting boom is to observe the frequency of its future usage.
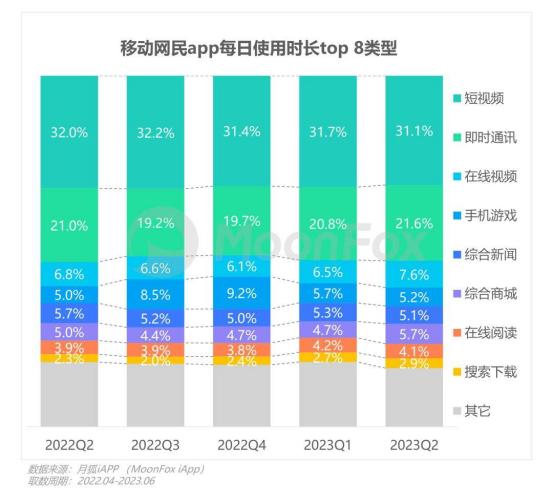
According to data from Moonfox iAPP, from Q2 2022 to June this year, short video apps accounted for over 30% of usage time across all categories of mobile internet applications, the highest among all categories.
Beyond the "vertical" dimension of time, when considering the vitality of a technology in spatial terms, the most crucial indicator is to see how wide a range of groups it can benefit.
For any technology to "survive," it must continuously propagate and diffuse itself like a living organism, adapting to different environments to increase diversity and stability.
For example, in the media sector, according to Tubular Labs' "2021 Global Video Index Report," viewership of news category videos increased by 40% year-over-year in 2020.
Similarly, in e-commerce, an Adobe survey found that approximately 60% of consumers prefer watching product videos over reading product descriptions when shopping.
In the healthcare field, a MarketsandMarkets report predicts that the global medical animation market will grow at a compound annual growth rate (CAGR) of 12.5% from 2020 to 2025.
In the financial industry, a HubSpot study shows that video content performs exceptionally well in conversion rates. Video content achieves conversion rates more than four times higher than text and image content.

Such demands indicate that, from both temporal and spatial dimensions, the field of video production is a vast 'reservoir' brimming with immense growth potential.
However, fully unleashing the potential of this 'reservoir' is no easy task.
In various industries, learning how to use complex video production tools (such as Adobe Premiere Pro, Final Cut Pro, or DaVinci Resolve) can be extremely challenging for non-professionals.
For professionals, video production remains a time-consuming process. They must start with storyboarding, plan the entire video's content and structure, and then proceed with shooting, editing, color grading, and more.
Sometimes, a mere 90-second advertisement video can take up to a month to produce.

From this perspective, opening up the field of AI-generated video is equivalent to removing the "blockage" in the pipeline connected to this reservoir.
After this, the hidden fountain of wealth will gush forth, bringing new increments and prosperity to various industries.
From this perspective, the text-to-video field, no matter how challenging, is the right and worthwhile path to pursue.
With the direction set, the next critical step is identifying which companies or teams will emerge as leaders in this space.
Currently, in the AI text-to-video arena, aside from the previously mentioned Pika, other similar companies are also making frequent moves.

Tech giants like Adobe Systems have acquired Rephrase.ai, Meta has launched Emu Video, Stability AI released Stable Video Diffusion, and Runway has updated RunwayML.
Just yesterday, the emerging AI video platform NeverEnds unveiled its latest 2.0 version.

Currently, applications like Pika, Emu Video, and NeverEnds have shown remarkable capabilities. The videos they generate are generally stable with reduced shaking.
However, to maintain a leading position in the AI text-to-video field in the long run, at least three key factors are required:
1. Powerful Computing Capability
In the field of video, AI's demand for computing power surpasses that of previous LLMs.
This is because video data contains higher temporal and spatial dimensions compared to image and text data. Additionally, to capture temporal dynamic information in videos, video models typically require more complex architectures.
More complex architectures mean more parameters, and more parameters imply exponentially greater computing power requirements.
Therefore, in the future AI video track, computing power resources will still be a 'hard threshold' that must be overcome.
2. Cross-Domain Collaboration
Compared to image or text large models, video large models typically involve more fields and are more comprehensive.
They require the integration of various technologies, such as efficient video analysis, generation, and processing. These include but are not limited to: image recognition, object detection, image segmentation, semantic understanding, etc.

If we compare current generative AI to a tree, then LLMs are the trunk, text-to-image models are the branches and flowers extending from the trunk, while video models are the most complex fruits that absorb nutrients from all parts (different types of data).
Therefore, how to facilitate cross-domain communication and collaboration through strong resource integration capabilities becomes the key determinant of a team's innovation capacity.
3. Technological Autonomy
As previously mentioned, in the current field of text-to-video generation, the industry has not yet formed a clear and unified technical approach like that of LLMs. Various directions are being explored.
In an undetermined technical direction, how to provide frontline technical personnel with greater tolerance, allowing them to continuously experiment and explore, becomes the key to building a team's innovation mechanism.
The best solution to this problem is to let technical personnel take the lead themselves, giving them the greatest "technical autonomy."
As Chenlin, the founder of Pika Labs, said: "If the training dataset isn't visually appealing, the characters learned by the model won't be either. Therefore, you ultimately need someone with artistic aesthetic judgment to select the dataset and control the quality of annotations."

Pika Labs founders Demi Guo and Chenlin Meng
In the context of relentless competition among enterprises and teams, along with the continuous emergence of new industry products, the explosive growth of text-to-video AI has become a very specific and anticipated trend.
According to Pika Labs founder Demi's assessment, the industry might witness the 'GPT moment' for AI video next year.
Despite the fact that technological development does not always follow human will, when the desire for a certain technology becomes an industry consensus and attracts more and more resources, the storm of transformation will inevitably arrive.