
Domestic AI Models Obsessed with 'Benchmarking': Relentlessly Pursuing High Scores
-
The phrase 'Let's run a benchmark if you disagree' is familiar to those in the smartphone community. Benchmarking tools like AnTuTu and GeekBench, which reflect device performance to some extent, have garnered significant attention from enthusiasts. Similarly, PC processors and graphics cards also have their respective benchmarking tools to measure performance.
Since 'everything can be benchmarked,' the hottest AI models have also joined the benchmarking trend. Especially after the 'Hundred Models War' began, breakthroughs are announced almost daily, with each company claiming to be 'number one in benchmarking.'
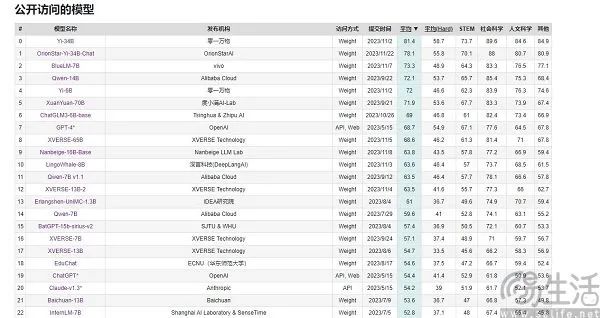
However, while domestic AI models have rarely lost in benchmarking, they have never surpassed GPT-4 in actual user experience. The question arises: during major promotions, smartphone manufacturers often claim 'sales number one' by adding qualifiers and segmenting the market further, ensuring everyone gets a 'first place.' But the AI model field is different—their evaluation benchmarks are largely unified, including MMLU (for measuring multitask language understanding), Big-Bench (for quantifying and extrapolating LLM capabilities), and AGIEval (for assessing performance on human-level tasks).
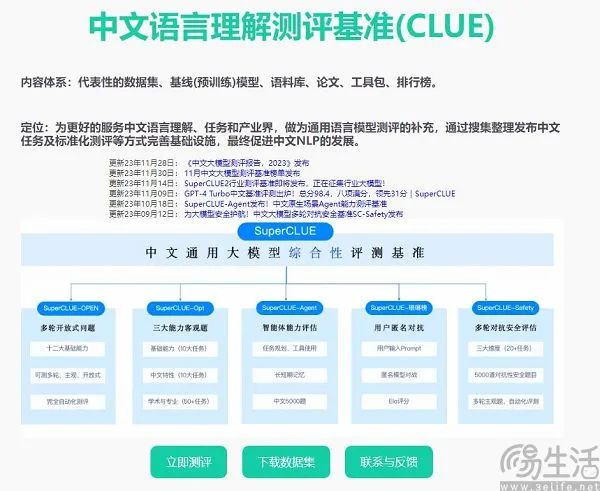
Currently, the large model evaluation benchmarks frequently cited by domestic manufacturers are SuperCLUE, CMMLU, and C-Eval. Among them, CMMLU and C-Eval are comprehensive exam evaluation sets jointly constructed by Tsinghua University, Shanghai Jiao Tong University, and the University of Edinburgh. CMMLU, on the other hand, was launched by MBZUAI, Shanghai Jiao Tong University, and Microsoft Research Asia. As for SuperCLUE, it was developed by a group of AI professionals from various universities.
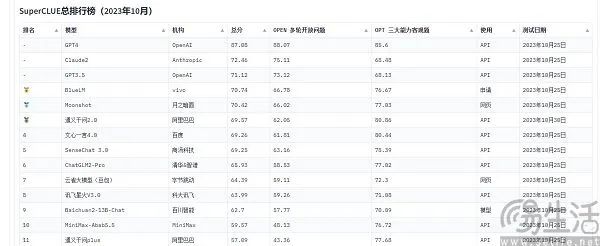
Taking C-Eval as an example, on the early September rankings, the large model "Yuntian Book" by Yuntian Lifei ranked first, 360 ranked eighth, while GPT-4 only ranked tenth. Since the standards are quantifiable, why do such counterintuitive results occur? The reason behind the chaotic appearance of large model benchmark rankings lies in the current limitations of evaluating AI model performance—they measure large model capabilities through standardized "test-taking" methods.
It is well-known that smartphone SoCs, computer CPUs, and GPUs automatically throttle performance at high temperatures to protect their lifespan, while lower temperatures allow the chips to perform better. Therefore, placing a phone in a refrigerator or equipping a computer with more robust cooling for benchmarking often yields higher scores than under normal conditions. Not to mention, "exclusive optimizations" for various benchmarking software have long become standard practice for major smartphone manufacturers.
Similarly, since AI model benchmarking primarily revolves around solving problems, there naturally exists a question bank. This is precisely why some domestic large models are fiercely competing in "leaderboard climbing." Due to various reasons, the question banks of major model benchmarks are almost unilaterally transparent to manufacturers, leading to what's known as "benchmark leakage." For instance, when the C-Eval benchmark was first launched, it contained 13,948 questions. Given the limited size of the question bank, there have been cases where lesser-known large models "aced" the benchmark by memorizing the questions.
Imagine if you happened to see the exam paper and standard answers before the test—cramming the answers would significantly boost your scores. Similarly, by incorporating the preset question banks of model benchmarks into their training sets, these large models essentially become models that fit the benchmark data. Moreover, current LLMs are already renowned for their exceptional memory, making memorizing standard answers a piece of cake.
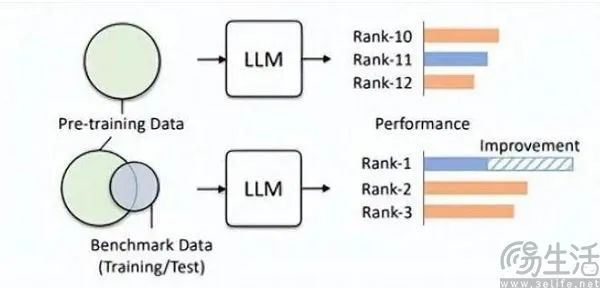
Through this approach, small-sized models can achieve better results in benchmarks than larger models, with some high scores of large models being achieved through such "fine-tuning." The Gaoling team from Renmin University explicitly pointed out this phenomenon in their paper Don't Make Your LLM an Evaluation Benchmark Cheater, noting that such shortcut practices are actually detrimental to the performance of large models.
The Gaoling team researchers found that benchmark leakage can lead to exaggerated performance in large models. For example, a 1.3B model can outperform models ten times its size on certain tasks. However, the side effect is that these large models, specifically designed for "test-taking," suffer adverse impacts on their performance in other normal testing scenarios. After all, it's easy to understand: AI models, which should be "problem solvers," become "rote memorizers." To achieve high scores on specific leaderboards, they use the particular knowledge and output styles of those benchmarks, which inevitably misleads the models.

The ideal scenario of non-overlapping training, validation, and test sets is just that—an ideal. Reality is harsh, and data leakage problems are almost unavoidable at their root. With the continuous advancement of related technologies, the memory and reception capabilities of the Transformer architecture, the foundation of current large models, are constantly improving. This summer, Microsoft Research's General AI strategy already enabled models to process 100 million tokens without unacceptable forgetting. In other words, future AI models may very well have the ability to read the entire internet.
Even setting aside technological advancements, data pollution is difficult to avoid with current technology alone, as high-quality data remains scarce and limited in production capacity. A paper published earlier this year by the AI research team Epoch suggests that AI will exhaust all high-quality human language data within five years. This prediction accounts for the growth rate of human language data, including books, research papers, and code written over the next five years.
A high-quality dataset suitable for evaluation purposes will inevitably perform better in pre-training. For example, OpenAI's GPT-4 utilized data from the authoritative reasoning benchmark GSM8K. This highlights the current dilemma in large model evaluation: the insatiable demand for data forces evaluation institutions to outpace AI model developers, yet these institutions currently lack the capability to do so.
Why are some companies so keen on manipulating benchmark rankings for large models? The logic behind this behavior mirrors app developers inflating user numbers. Just as user scale is a key metric for app valuation, benchmark scores are currently the only relatively objective measure for evaluating AI models in their early stages. In the public eye, higher scores equate to superior performance.
When benchmarking may bring strong publicity effects and even lay the foundation for financing, the involvement of commercial interests will inevitably drive AI model vendors to compete in benchmarking.