
Tech Giants Frenziedly Compete for AI Data Annotators: Monthly Salary of 20K, Becoming AI Model Examiners, Easy Money!
-
"Average monthly salary of 20K, bachelor's degree or above, direct access to Baidu and ByteDance."
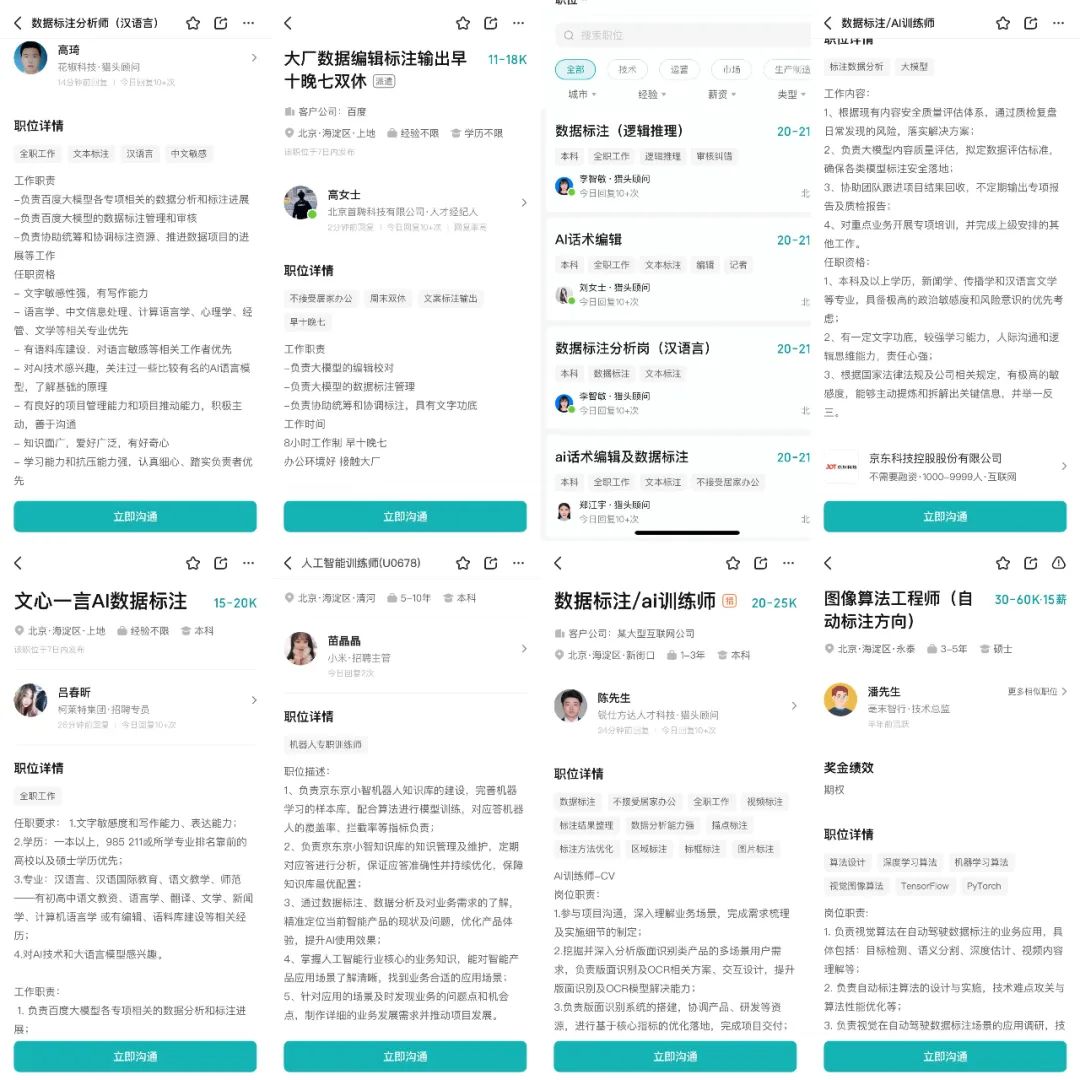
In the somewhat bleak year-end job market, a large number of "AI data annotator" positions have suddenly emerged within just the past week, with intense recruitment underway.
According to searches by "Self Quadrant," these positions are not only offered by "dream companies" like Baidu, ByteDance, JD.com, Didi, and Meituan but also come with eye-catching monthly salaries ranging from 10K to 20K. Moreover, the postings are very recent, all within the last week to a month.
In addition to being new, the recruitment for these positions is evidently very urgent. Job platforms show that HR personnel are unusually active, almost online 24/7, with daily response rates exceeding ten times, replying every few minutes.
"Recently, as soon as I log in, recruitment messages for AI data annotators pop up incessantly, repeating over and over," many job seekers told [Self Quadrant]. "The last time I saw such aggressive outreach was during the live-streaming host recruitment boom."
The hiring frenzy inevitably brings to mind the battle among tech giants over large-scale models.
However, according to observations by [Self Quadrant], the recruitment for "AI data annotators" is not directly handled by these major companies but is instead outsourced to headhunting firms. The job titles vary widely, including "data annotator," "AI script editor," "data annotation analyst," "annotator," "AI trainer," and more.
Although the titles differ, the job descriptions for these positions are largely similar. According to recruitment software information, a significant portion of these roles are related to the currently trending large models. The daily tasks of data annotators include editing and proofreading large models, managing data annotations for large models, and evaluating the content quality of large models.
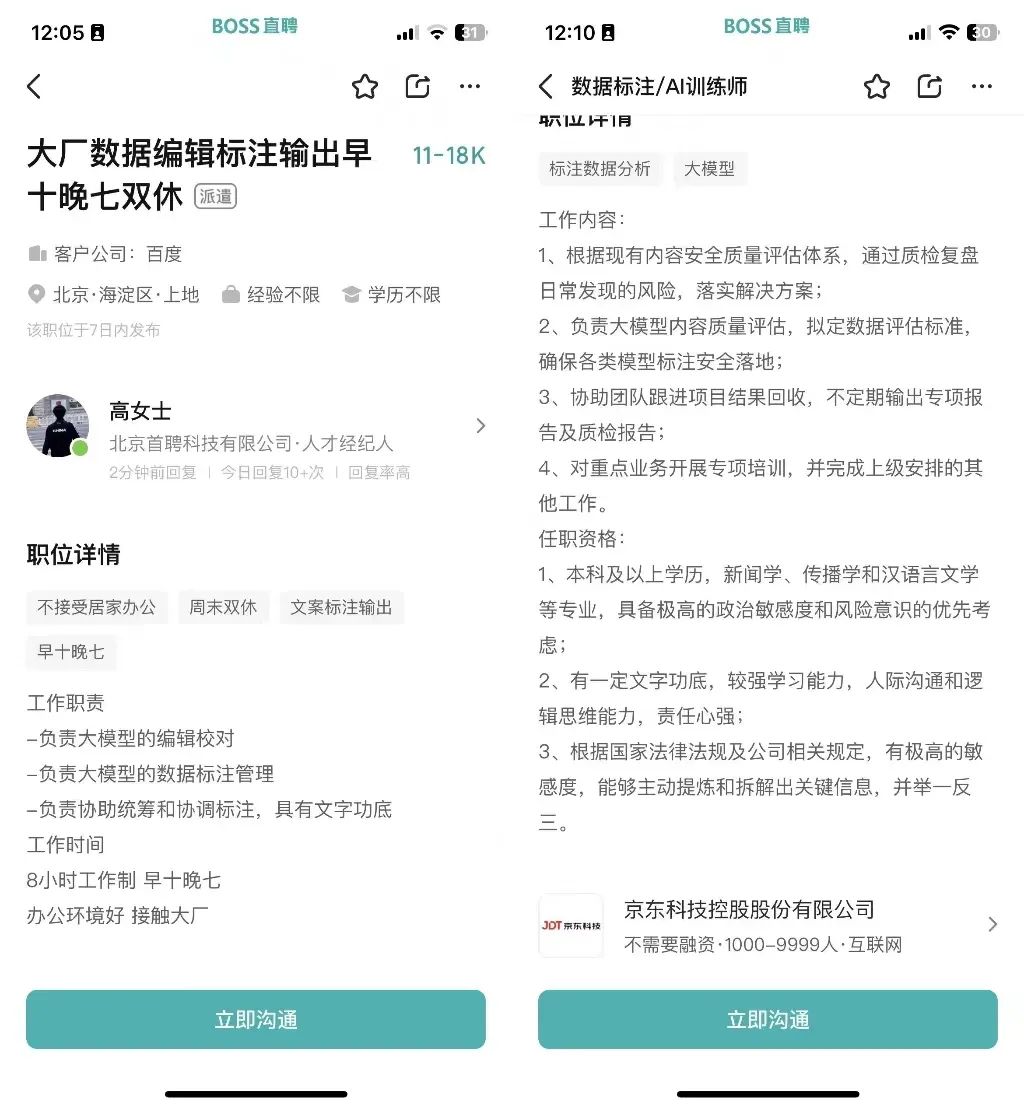
"The main task is to analyze and evaluate the responses generated by the Wenxin Yiyan large model, and the work location is at Baidu Technology Park," replied a headhunter when consulted by "Self Quadrant."
High salaries, ties to large models, and fierce competition among tech giants... Some job seekers see opportunities, wondering, "Will the wave of large models bring new opportunities for ordinary people to settle in big tech companies?"
However, in reality, the recruitment for these time-sensitive and high-pressure positions is not easy. The basic educational requirement is a bachelor's degree, with preference given to graduates from 985 or 211 universities. Candidates must also have a background in linguistics, Chinese information processing, computational linguistics, literature, or related fields, along with an understanding of AI technology principles.
Huajiao Technology shared that the interview process typically involves "resume screening, a written test, a first-round interview, a direct offer, and training." Regarding education, headhunters emphasize that "a degree from a top-tier university is a must, with 211/985 graduates preferred."
Behind the strict entry requirements and the mysterious "AI Data Annotator" job postings on recruitment platforms lies the grand strategy of tech giants in the large model arena.
After over a month of interviews, Luo Wen (pseudonym), a Chinese literature graduate, finally secured her offer—an AI data annotator for Baidu's ERNIE Bot. Even she couldn’t believe that a complete tech novice like her would now spend her days acting as an "examiner" for large models.
"After graduating three years ago with no AI experience, I transitioned careers and saw a nearly 50% salary increase, now earning between 9k-15k monthly," Luo Wen shared with us.
Sitting in front of two computers, Luo Wen's daily tasks primarily involve two things: first, solving problems—essentially 'force-feeding' pre-written answers to large AI models; second, acting as a 'judge' for Wenxin Yiyan, evaluating whether the provided answers are correct and of good quality.
The so-called 'force-feeding' means forcibly inputting prepared answers into large AI models. The benefit of this approach is ensuring no errors at the data source, thereby improving the training effectiveness of the models. Luo Wen told us she has worked on math problems, general knowledge questions, and essay topics, but this is far from enough. "Theoretically, the more specialized the better. For example, if I excel in literature, I focus on literature questions. Some colleagues specialize in medicine, so they handle medical Q&A," Luo Wen explained.
Luo Wen's account has been corroborated on some social platforms, where posts have appeared stating, 'Urgently recruiting finance professionals to answer questions for Wenxin Yiyan on a paid basis—30+ questions per day, with each question priced between 1.5-2.4 yuan.'

Another job is being a 'grading teacher' for large models. Just like students taking exams, large models generate answers to various questions every day. Luo Wen needs to play the role of a teacher, judging whether the generated answers are consistent with the questions and whether the answers are correct.
When encountering open-ended questions without standardized answers, such as essays, it is necessary to evaluate the quality of the answers. For example, the system will randomly provide a set of data containing one question and three answers. Luo Wen first needs to label what type of question it is, then score and rank the three answers. The score range is 0-5 points. If the score is below 3 points, specific reasons must be noted, such as "irrelevant answer (0 points)," "severely off-topic (1 point)," or "logical issues, minor factual errors, giving 2 points," etc.
Although this job may not appear difficult, it is exceptionally important and can even serve as a direct pathway from outsourcing to major tech companies. According to the headhunter mentioned above, "Although the contract is signed with our headhunting firm, there's still a one in six chance of converting to a full-time position and joining Baidu Group." This might also explain the strict educational requirements.
▲ Source: Boss Zhipin Screenshot
In this regard, "Self Quadrant" has also learned that due to Baidu Maps' data annotation needs—which include stable map business requirements and training demands for autonomous driving and algorithm models—the quality standards for data annotation are higher. Indeed, Baidu has established a dedicated data annotation team.
The demand for 'Rowan' in the market is not limited to large model companies. According to statistics from 'Self Quadrant', data annotation jobs in the market are generally divided into two types.
One focuses on NLP (Natural Language Processing), where tech giants like Baidu, ByteDance, JD.com, and Meituan are actively recruiting human data trainers for their large models. This category further branches into several specialized areas, such as data analysis, evaluation of large model outputs, and assisting in the logical reasoning of large models.
The other direction is CV (Computer Vision), which has been around for a long time. The more familiar tasks include '2D bounding box' and '3D bounding box,' primarily serving automotive companies like Didi, Haomo, and Qingzhou Zhihang. These tasks provide image data quality inspection and annotation support for their autonomous driving businesses.
▲Image source: Boss Zhipin screenshot
"Self Quadrant" observations reveal that November marked a turning point for NLP data annotation. Previously, major companies like Baidu and JD.com offered very few or no AI data annotation positions, whether for campus recruitment or social recruitment. Job platforms only sporadically listed internship positions, typically with no minimum education requirement but capped at associate degree level.
The sudden emergence of numerous job openings without warning may be related to research obstacles encountered by large model developers. Multiple industry insiders have disclosed to "Self Quadrant" that, as of now, domestic large models may only reach GPT-3.5 level, with data quality remaining the core challenge for development.
While OpenAI internationally continues to make significant strides toward GPT-5, domestic companies are pressured to "implement" and "utilize large models," resorting to "human wave tactics" under this dual pressure.
When technical R&D falls short, human effort fills the gap. Domestic large model manufacturers have begun frenzied recruitment of "AI data annotators" to add more fuel to the "ascent" of large model capabilities.
In fact, data annotation is not a new concept and has existed for some time. Previously, the approach was crude labeling, primarily manifested as "bounding box drawing." However, crude labeling has now become chaotic: first, major companies previously relied on crowdsourced labeling platforms, where tasks were fragmented and personnel were unprofessional, resulting in poor labeling quality; second, as large models advance, crude labeling has become increasingly inadequate, causing the importance of refined labeling to skyrocket.
Regarding the differences between crude and refined labeling, an employee from a major company explained: "General outsourcing teams can perform labeling, but they strictly follow predefined rules. If data falls outside these rules, the labeling process often faces low approval rates and repeated iterations. However, when engineering teams handle it—especially for data feedback in areas like autonomous driving assistance—they understand the underlying principles. They may not label according to conventional thinking but instead approach it with problem-solving perspectives, potentially deviating from established labeling rules. This results in higher-quality labeled data."
The explosion of large models has also sparked a "new gold rush" in crude labeling.
Currently, the primary job hunting ground for data annotation has shifted from recruitment software to short video platforms like Kuaishou. Taking Kuaishou as an example, the popularity of data annotation job searches is on par with that for courier positions. Numerous data annotation companies have set up shop on Kuaishou, covering regions such as Beijing-Tianjin-Hebei, the Yangtze River Delta, and the Pearl River Delta.
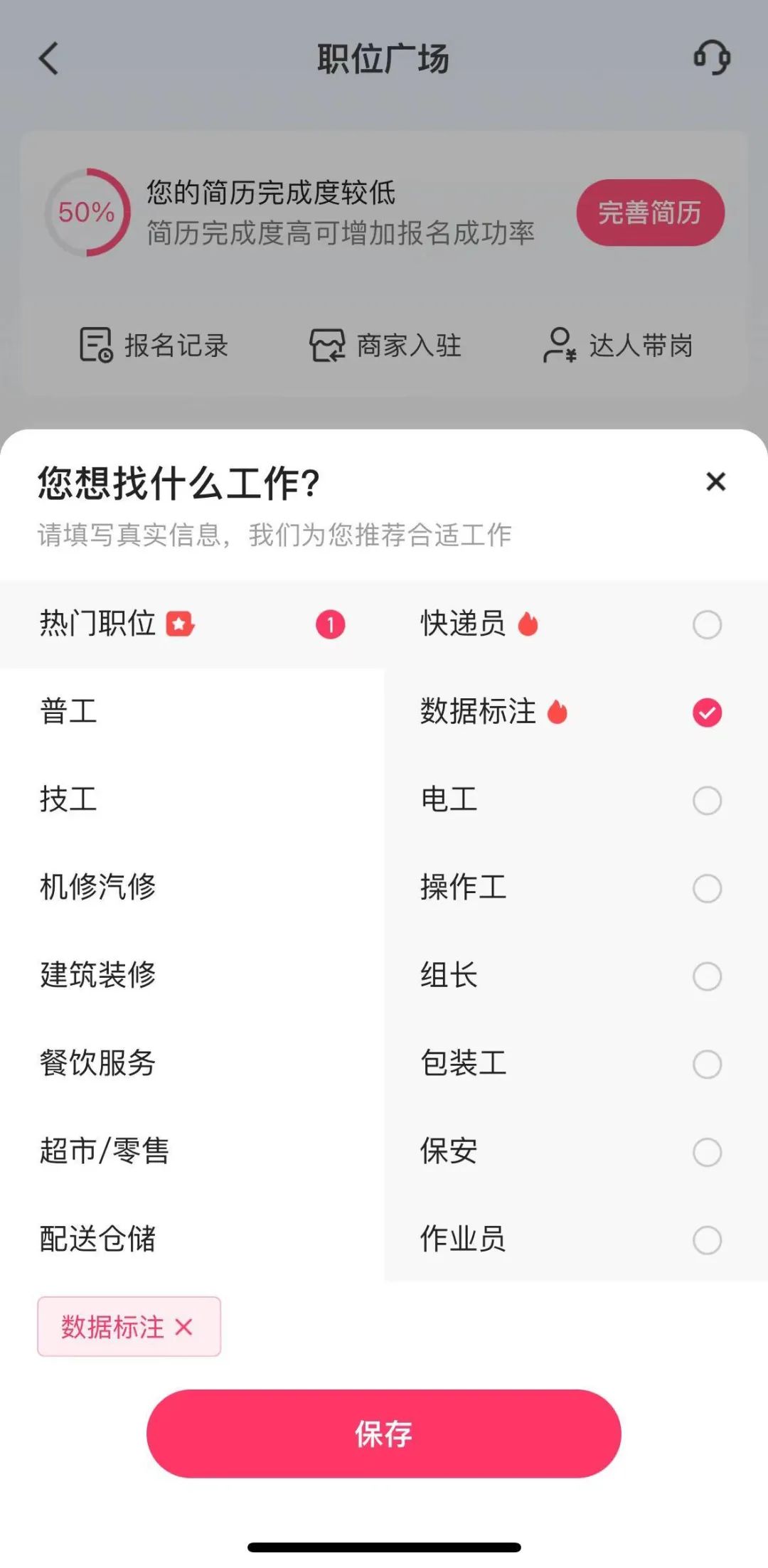
According to insights from "Self Quadrant," Kuaishou's live-streaming recruitment service "KuaiPin" specifically mentioned in a press conference: "We aim to address the core challenges of difficult offline recruitment and a shortage of applicants for data annotation positions."
Kuaishou has provided comprehensive support for data annotation companies, ranging from qualification reviews and traffic support to company recommendations and job promotion. "Self-Quadrant" noticed that Kuaishou's official recruitment livestreams sometimes continuously broadcast job information for data annotation roles around the clock.
This has, to some extent, become a "golden ticket" for certain data annotation companies. During recruitment, these companies make unrestrained claims like "No education required, easy to learn, even elementary school students can do it," "Draw a box, add a label, and you’ve earned half a dollar," and "3,000 boxes for ¥150, 6,000 for ¥300, earning ¥7,000-8,000 a month is a breeze—just be fast enough." The exaggerations are extreme.
But what’s the reality? Can you really earn ¥10,000 so easily?
To investigate, "Self-Quadrant" contacted a popular data annotation company on Kuaishou. The company claimed to have direct contracts with automakers like BYD, Li Auto, XPeng, and Tesla, securing first-hand data tasks. It also presented numerous certificates and documents to emphasize its legitimacy. The main task after joining was to accept task packages, draw boxes, annotate, and label images.

▲WeChat Screenshot
Here are the key points:
- Payment is calculated per annotation box, with each box priced between 0.10 to 0.15 yuan
- First month's salary is paid weekly, then monthly from the second month
- Newcomers must pay a 2,580 yuan training fee, refundable only after earning 10,000 yuan within one year
- Average training period is about seven days before starting tasks
- Offers both part-time (paid per box) and full-time positions (onsite work with free accommodation provided)
- Shown employee salary screenshots indicate monthly earnings ranging from 5,000 to 6,000 yuan
However, the mentioned company has become a major target of data annotation complaints on consumer complaint platforms.
Some user complaints align with our experiences. Based on user feedback, the main issues include:
- Requirement to pay 2580 yuan upfront for annotation tasks with promised refunds after completing 10,000 yuan worth of work, but the platform refuses to honor refunds
- Overly simplistic training content that consumes excessive time, delaying users' onboarding
- Unreasonably low approval rates for annotation work, significantly impacting earnings
- Aggressive customer service attitude that ignores user complaints and refuses to process refunds
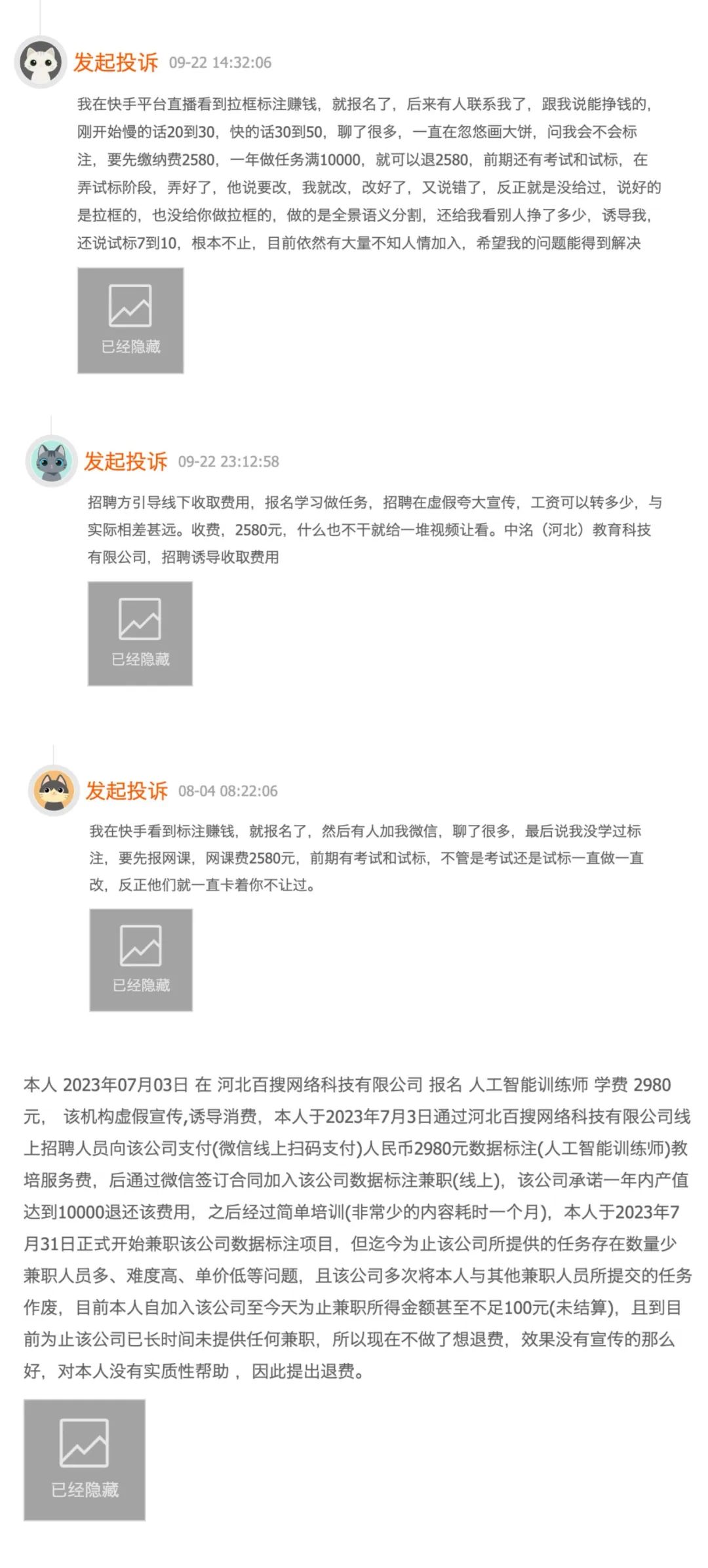
▲Screenshot from Heimao complaint platformThese issues represent just the tip of the iceberg. Although we didn't complete the payment process, our team at Zixiangxian received constant harassment through phone calls and WeChat messages after initial inquiries - from morning greetings to goodnight messages, along with frequent taunts showing other employees' payment records.
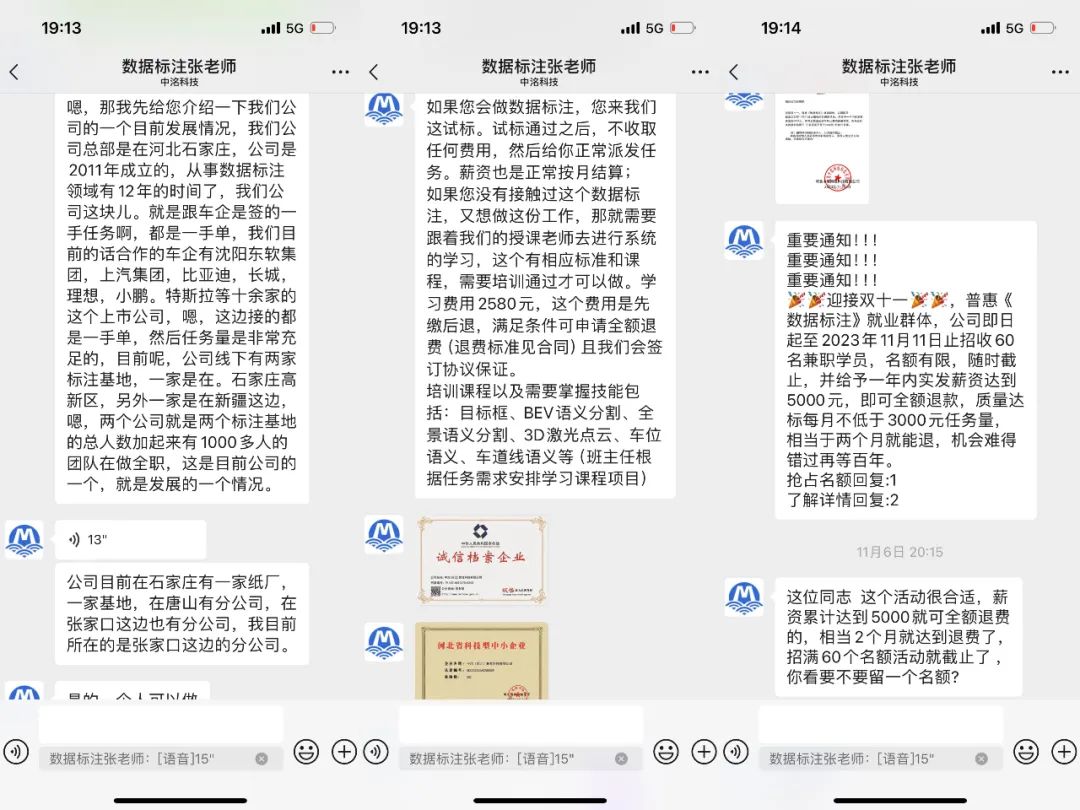
▲Source: WeChat Screenshot
A serious data annotation job search has turned into a 'Ponzi scheme,' where honest workers labeling boxes earn nothing, while data annotation companies collecting training fees make huge profits.
Data quality determines the speed at which large models progress, and even OpenAI is no exception. Foreign media reports indicate that OpenAI has hired several well-known data companies for data annotation while also assembling an in-house team of dozens of philosophy PhDs to oversee data quality control.
The foundation of large models lies in data. Data quality directly determines the evolution speed of large models. From the chaos in data labeling, we might get a glimpse of why China's large model development is progressing slowly. But now that large model manufacturers have recognized the root issue of data labeling, we might not be far from truly breaking through to GPT-4.