
Microsoft Open-Sources VibeVoice TTS Model: 90-Minute Ultra-Long Speech, Supports 4-Person Dialogue, Stunning Chinese Performance!
-
Recently, Microsoft launched a highly anticipated open-source text-to-speech (TTS) model—VibeVoice, sparking significant attention in the AI voice technology field. With its powerful features and exceptional performance, this model sets a new benchmark for long-form speech generation, multi-person dialogue, and Chinese speech synthesis. Below, AIbase will provide a detailed analysis of VibeVoice's highlights and potential.
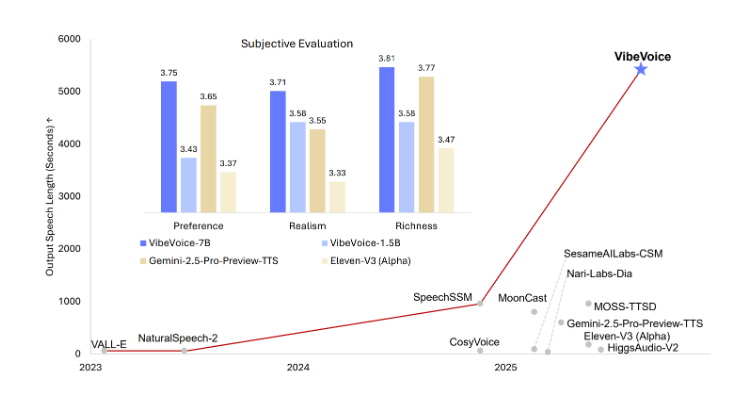
Supports 90-Minute Ultra-Long Speech Generation, Breaking Duration Limits
The VibeVoice model achieves a major breakthrough in speech generation duration, capable of producing up to 90 minutes of continuous speech in one go. This feature is particularly suitable for scenarios requiring long-duration audio output, such as podcasts, audiobooks, and educational content production. Compared to the duration limitations of traditional TTS models, VibeVoice's ultra-long generation capability offers content creators greater flexibility and creative freedom.
New Heights in Multi-Person Dialogue, Supports Up to 4 Voices
Unlike previous TTS models limited to single or dual-person dialogues, VibeVoice can seamlessly generate conversations involving up to four voices. This feature excels in scenarios like simulating multi-person podcasts, meeting recordings, or virtual character interactions. Thanks to its optimizations in voice consistency and natural turn-taking, VibeVoice's multi-person dialogue output is smooth and natural, almost indistinguishable from real human recordings.
Exceptional Chinese Speech Performance, Boosting Localized Applications
For the Chinese market, VibeVoice delivers impressive performance. It supports Chinese speech synthesis with high levels of accuracy in tone, pronunciation, and naturalness. This makes VibeVoice highly applicable in fields like Chinese podcasts, education and training, and intelligent customer service, providing developers with a high-quality localized voice solution.
Supports Background Music, Creating Immersive Podcast Experiences
Another standout feature of VibeVoice is its ability to generate podcast audio with background music. This allows content creators to easily add sound effects, creating more immersive and professional audio content. Whether it's a light background melody or tense ambient effects, VibeVoice seamlessly integrates them for a richer auditory experience.
Open-Source Empowerment for Developers, Broad Future Applications
As an open-source model, VibeVoice was officially released on GitHub on August 26, 2025, allowing developers to freely access and modify it. Microsoft's open-source initiative not only lowers the barrier to high-quality TTS technology but also injects new vitality into the global AI developer community. Both individual creators and enterprise users can leverage VibeVoice to quickly build innovative voice applications.