
Apple Introduces New AI Training Method Using Task Checklists to Replace Manual Scoring, Significantly Improving Model Performance
-
Apple's research team recently proposed an innovative training method called 'Reinforcement Learning from Checklist Feedback' (RLCF) in their latest paper. By replacing traditional manual like/dislike scoring mechanisms with specific task checklists, this approach significantly enhances large language models' ability to execute complex instructions.
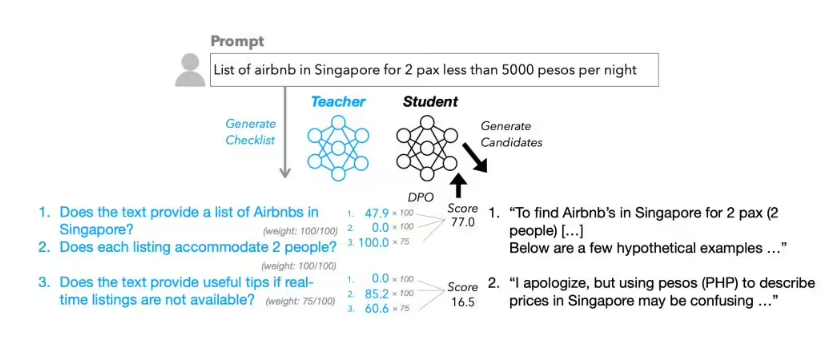
RLCF, short for Reinforcement Learning from Checklist Feedback, stands in stark contrast to the widely used 'Reinforcement Learning from Human Feedback' (RLHF) method. While traditional RLHF relies on simple like/dislike evaluations by humans, RLCF generates detailed checklists for each user instruction and provides precise 0-100 scoring for each item, serving as guidance for model optimization.
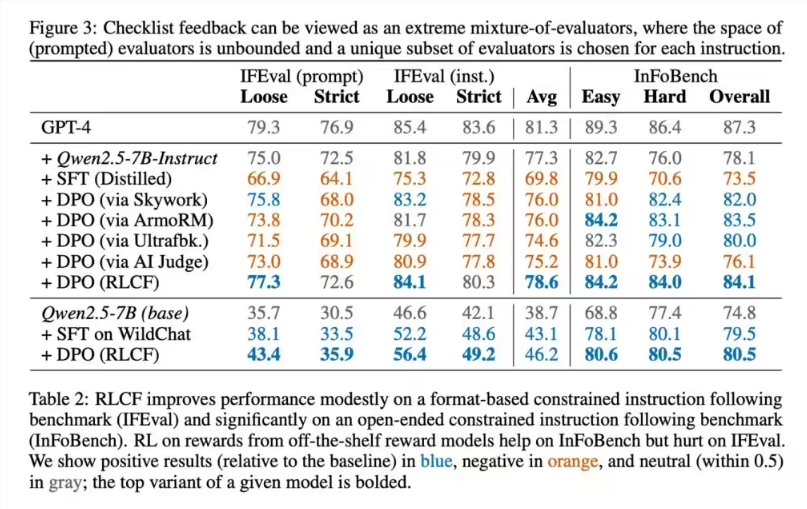
Apple's research team selected the strong instruction-following model Qwen2.5-7B-Instruct as the test subject and conducted comprehensive validation across five commonly used evaluation benchmarks. Test results showed that RLCF was the only training solution that achieved performance improvements across all test items.
Specific data revealed a 4 percentage point increase in hard satisfaction rate in the FollowBench test, a 6-point improvement in InFoBench scores, and a 3-point increase in Arena-Hard win rate. In certain specific tasks, performance improvements reached up to 8.2%. These results indicate that the checklist feedback method performs particularly well in handling complex multi-step tasks.
In terms of technical implementation, Apple's checklist generation process is highly innovative. They used the larger-scale Qwen2.5-72B-Instruct model, combined with existing research methods, to create a specialized dataset called 'WildChecklists' for 130,000 instructions. The checklist items were designed as clear binary judgments, such as 'whether translated into Spanish' and other specific requirements. The large model then scored candidate responses item by item, and through comprehensive weighted processing, formed training reward signals to guide the learning and optimization process of smaller models.
However, Apple researchers also candidly acknowledged the limitations of this method. First, RLCF relies on more powerful models as evaluation standards, which may pose implementation challenges in scenarios with limited computational resources. Second, the method is specifically designed to improve complex instruction execution capabilities and is not intended for safety alignment purposes, so it cannot replace existing safety evaluation and tuning mechanisms. For other types of AI tasks, the applicability of the RLCF method requires further experimental validation.
Industry experts believe that Apple's proposed RLCF method offers a new approach to AI model training, demonstrating clear advantages, particularly in handling complex multi-step tasks. With further technological refinements, this method is expected to play a greater role in practical applications.